

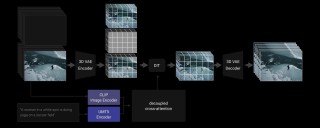
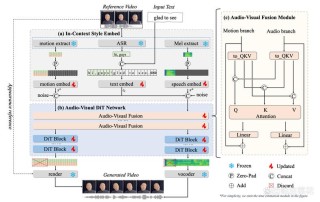
DiffuEraser是基于稳定扩散模型的视频修复模型,以更丰富的细节和更连贯的结构填充视频中的遮罩区域。模型通过结合先验信息来提供初始化和弱条件,有助于减少噪声伪影和抑制幻觉。为了在长序列推理期间提高时间一致性,DiffuEraser 扩展了先验模型和自身的时间感受野,进一步基于视频扩散模型的时间平滑特性来增强一致性。 DiffuEraser 的网络架构受 AnimateDiff 的启发,将运动模块集成到图像修复模型中。主要由主去噪 UNet 和辅助的 BrushNet 组成。BrushNet 分支接收由遮罩图像、遮罩和噪声潜变量组成的条件潜变量输入。BrushNet 提取的特征在经过零卷积块后逐层整合到去噪 UNet 中。去噪 UNet 处理噪声潜变量。为了增强时间一致性,模型在自注意力和交叉注意力层之后引入了时间注意力机制。去噪后,生成的图像使用模糊遮罩与输入的遮罩图像进行融合。

(图片来源网络,侵删)

(图片来源网络,侵删)







全部评论
留言在赶来的路上...
发表评论