

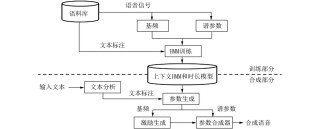
Dolphin是清华大学电子工程系语音与音频技术实验室联合海天瑞声共同推出的面向东方语言的语音大模型。支持40个东方语种的,中文语种涵盖22种方言(含普通话),能精准识别不同地区的语言特点。模型训练数据总时长21.2万小时,高质量专有数据13.8万小时,开源数据7.4万小时。在性能上,Dolphin的词错率(WER)显著低于Whisper同等尺寸模型,如base版本平均WER降低63.1%,small版本降低68.2%。采用CTC-Attention架构,结合E-Branchformer编码器和Transformer解码器,通过4倍下采样层加速计算,保留关键语音信息。

(图片来源网络,侵删)

(图片来源网络,侵删)





全部评论
留言在赶来的路上...
发表评论