

Emu3是由北京智源人工智能研究院推出的一款原生多模态世界模型,采用智源自研的多模态自回归技术路径,在图像、视频、文字上联合训练,使模型具备原生多模态能力,实现图像、视频、文字的统一输入和输出。Emu3将各种内容转换为离散符号,基于单一的Transformer模型来预测下一个符号,简化了模型架构。Emu3在图像生成方面,只需一段文本描述可创造出符合要求的高质量图像,表现超越了专门的图像生成模型SDXL。在图像和语言的理解能力上,Emu3能准确描述现实世界场景给出恰当的文字回应,无需依赖CLIP或预训练的语言模型。Emu3能延续现有视频内容,自然地扩展视频场景。

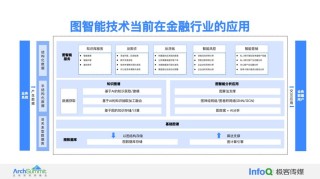
(图片来源网络,侵删)

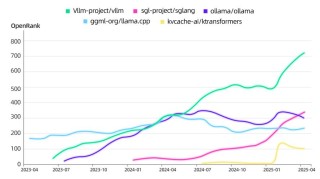
(图片来源网络,侵删)






全部评论
留言在赶来的路上...
发表评论