

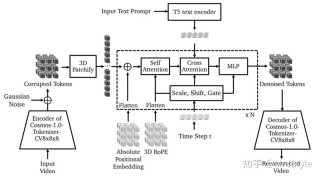
GAS(Generative Avatar Synthesis from a Single Image)是卡内基梅隆大学、上海人工智能实验室和斯坦福大学的研究人员提出的从单张图像生成高质量、视角一致且时间连贯虚拟形象的框架。GAS的核心在于结合了回归型3D人体重建模型和扩散模型的优势。基于3D人体重建模型从单张图像生成中间视角或姿态,将其作为条件输入视频扩散模型,实现高质量的视角一致性和时间连贯性。框架引入了“模式切换器”,用于区分视角合成和姿态合成任务,进一步提升生成效果。

(图片来源网络,侵删)

(图片来源网络,侵删)

全部评论
留言在赶来的路上...
发表评论