

OmniCorpus是一个大规模多模态数据集,包含86亿张图像和16960亿个文本标记,支持中英双语。由上海人工智能实验室联合多所知名高校及研究机构共同构建。OmniCorpus通过整合来自网站和视频平台的文本和视觉内容,提供了丰富的数据多样性。与现有数据集相比,OmniCorpus在规模和质量上都有显著提升,推动多模态大语言模型的研究和应用。数据集在GitHub上公开可用,适用于多种机器学习任务。

(图片来源网络,侵删)

(图片来源网络,侵删)
OmniCorpus是一个大规模多模态数据集,包含86亿张图像和16960亿个文本标记,支持中英双语。由上海人工智能实验室联合多所知名高校及研究机构共同构建。OmniCorpus通过整合来自网站和视频平台的文本和视觉内容,提供了丰富的数据多样性。与现有数据集相比,OmniCorpus在规模和质量上都有显著提升,推动多模态大语言模型的研究和应用。数据集在GitHub上公开可用,适用于多种机器学习任务。

PGTFormer是先进的视频人脸修复框架,通过解析引导的时间一致性变换器来恢复视频中的高保真细节,同时增强时间连贯性。该方法无需预对齐,基于语义解析选择最佳人脸先验,并通过时空Transformer模块和时序保真度调节器,...

PDFtoChat 是一个开源的创新AI项目,支持用户基于自然语言对话的方式与 PDF 文件互动。工具基于最新的 AI 技术,包括 Together AI 和 Mixtral,理解用户的查询,从 PDF 内容中提取相关信息。...
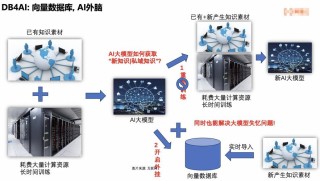

PDFMathTranslate是开源的PDF文档翻译工具,设计用于翻译科技论文等PDF文件,能保留原文的排版,包括公式和图表。PDFMathTranslate支持双语对照,保持原有目录结构,兼容多种翻译服务,如Google...

PDF2Audio 是一个开源工具,能将 PDF 文档转换成音频内容,适合制作播客、讲座或摘要。它基于 OpenAI 的 GPT 模型生成播客脚本,通过文本到语音技术转化为音频。...

PDF to Podcast是NVIDIA推出的PDF转音频的AI工具,基于NVIDIA NIM微服务架构的,能将PDF文档转换为生动的音频内容,如播客。基于大型语言模型(LLM)、文本到语音(TTS)技术以及NVIDIA的...
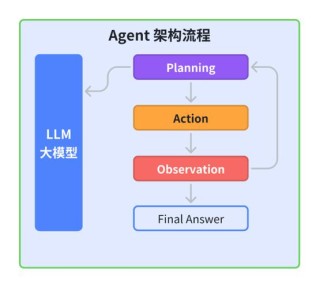
PC Agent-E是上海交通大学和SII联合推出的高效智能体训练框架。框架用312条人类标注的计算机使用轨迹,基于Claude 3.7 Sonnet模型合成多样化的行动决策,显著提升数据质量。...
PC Agent是上海交通大学和Generative AI Research Lab (GAIR 联合推出的先进AI系统。系统基于模拟人类认知过程,执行如组织研究材料、起草报告和创建演示文稿等复杂数字工作。PC Agent集...

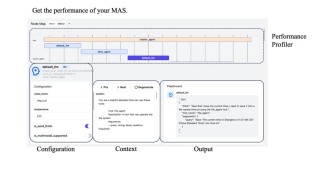
OxyGent是京东零售Oxygen团队开源的多智能体协作框架,能帮助开发者高效组装多智能体系统。OxyGent将工具、模型和智能体抽象为可插拔的模块(Oxy),支持像搭积木一样灵活组合,具备极致可扩展性和全链路决策追溯能力...
全部评论
留言在赶来的路上...
发表评论