

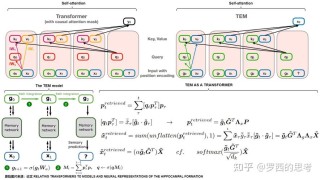
PRefLexOR(Preference-based Recursive Language Modeling for Exploratory Optimization of Reasoning)是MIT团队提出的新型自学习AI框架,结合了偏好优化和强化学习(RL)的概念,模型能通过迭代推理改进自我学习。框架的核心是递归推理算法,模型在训练和推理阶段会进行多步推理、回顾和改进中间步骤,最终生成更准确的输出。PRefLexOR的基础是优势比偏好优化(ORPO),模型通过优化偏好响应和非偏好响应之间的对数几率来对齐推理路径。集成了直接偏好优化(DPO),通过拒绝采样进一步提升推理质量。

(图片来源网络,侵删)

(图片来源网络,侵删)







全部评论
留言在赶来的路上...
发表评论