

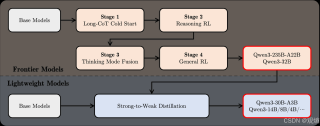
Parler-TTS是由Hugging Face推出的一款开源的文本到语音(TTS)模型,能够通过输入提示描述模仿特定说话者的风格(性别、音调、说话风格等),生成高质量、听起来自然的语音。该轻量级的TTS模型是完全开源的,包括所有数据集、预处理、训练代码和权重都公开,旨在促进高质量、可控制的TTS模型的创新发展。Parler-TTS的架构基于MusicGen,包含文本编码器、解码器和音频编解码器,通过集成文本描述和添加嵌入层优化了声音生成。
Parler-TTS的架构是一个高度灵活和可定制的系统,基于MusicGen架构进行了一些关键的改进和调整:

(图片来源网络,侵删)

(图片来源网络,侵删)







全部评论
留言在赶来的路上...
发表评论