

Qwen3 是阿里巴巴推出的新一代大型语言模型,Qwen3 支持“思考模式”和“非思考模式”两种工作方式,思考模式模型会逐步推理,经过深思熟虑后给出最终答案,适合复杂问题。非思考模式模型提供快速、近乎即时的响应,适用于简单问题。Qwen3 支持 119 种语言和方言,相比前代的 29 种语言,语言能力大幅提升。Qwen3 优化了编码和 Agent 能力,支持 MCP 协议,能更好地与外部工具和数据源集成。Qwen3 的数据集规模达到约 36 万亿个 token,是 Qwen2.5 的两倍。采用四阶段训练流程,包括长思维链冷启动、长思维链强化学习、思维模式融合和通用强化学习。Qwen3 系列模型采用 Apache 2.0 协议开源,全球开发者、研究机构和企业均可免费下载并商用。
阿里巴巴最新开源的两款Qwen3系列模型,Qwen3-Embedding和Qwen3-Reranker。
Qwen3-Embedding:在多语言文本表征基准测试中,Qwen3-Embedding的性能非常出色。其中,8B参数规模的模型在MTEB多语言Leaderboard榜单中以70.58的高分位列第一,超越了众多商业API服务,例如谷歌的Gemini-Embedding。接收单段文本作为输入,取模型最后一层「EOS」标记对应的隐藏状态向量,作为输入文本的语义表示。适用于需要对文本进行语义表征的场景,如文本分类、聚类、相似度计算等,能够为下游任务提供高质量的文本特征。

Qwen3-Reranker:在基本相关性检索任务中,8B模型在多语言检索任务中取得了69.02的高分,在中文检索任务中得分达到77.45,在英文检索任务中得分达到69.76,显著优于其他基线模型。接收文本对(例如用户查询与候选文档)作为输入,利用单塔结构计算并输出两个文本的相关性得分。用于文本检索和排序任务,如搜索引擎中的结果排序、问答系统中的答案排序等,能够提升搜索结果的相关性和准确性。
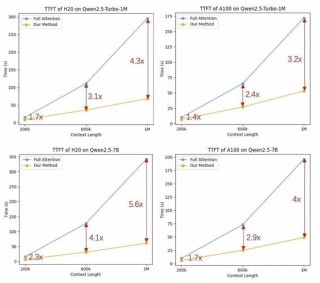
Qwen3 在多个基准测试中表现出色,例如:








全部评论
留言在赶来的路上...
发表评论