

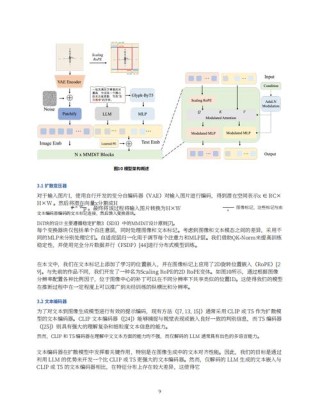
SeedFoley 是字节跳动豆包大模型语音团队开发的端到端视频音效生成模型,为视频创作提供智能音效生成服务。通过融合时空视频特征与扩散生成模型,实现音效与视频的高度同步。模型采用快慢特征组合的视频编码器,提取视频的时空特征,同时基于原始波形作为输入的音频表征模型,保留高频信息,提升音效细腻程度。扩散模型通过优化概率路径上的连续映射关系,减少推理步数,降低推理成本。 SeedFoley 能精准提取视频帧级视觉信息,智能区分动作音效和环境音效,支持多种视频长度,在音效准确性、同步性和匹配度上表现优异。

(图片来源网络,侵删)

(图片来源网络,侵删)






全部评论
留言在赶来的路上...
发表评论