

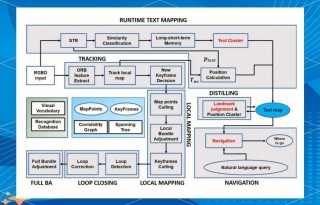
TIGER(Time-frequency Interleaved Gain Extraction and Reconstruction Network)是清华大学研究团队提出的轻量级语音分离模型,通过时频交叉建模策略,结合频带切分和多尺度注意力机制,显著提升了语音分离的效果,降低了参数量和计算量。 TIGER 的核心在于创新的时频交叉建模模块(FFI),能高效整合时间和频率信息,更好地提取语音特征。模型引入多尺度选择性注意力模块(MSA)和全频/帧注意力模块(F³A),进一步优化了特征提取能力。

(图片来源网络,侵删)

(图片来源网络,侵删)





全部评论
留言在赶来的路上...
发表评论