

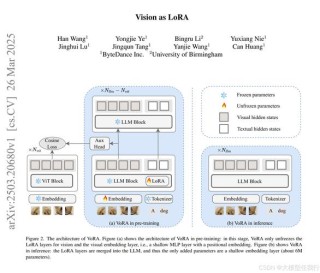
TextHarmony是华东师范大学和字节跳动共同推出的多模态生成模型,擅长理解和生成视觉文本。模型基于Slide-LoRA技术,动态聚合特定于模态和模态无关的LoRA专家,部分解耦多模态生成空间,在单一模型实例中协调视觉和语言的生成。TextHarmony在视觉和语言模态之间实现更统一的生成过程。研究团队推出高质量的图像字幕数据集DetailedTextCaps-100K,基于高级闭源MLLM合成,进一步提升模型的视觉文本生成能力。

(图片来源网络,侵删)

(图片来源网络,侵删)
TextHarmony是华东师范大学和字节跳动共同推出的多模态生成模型,擅长理解和生成视觉文本。模型基于Slide-LoRA技术,动态聚合特定于模态和模态无关的LoRA专家,部分解耦多模态生成空间,在单一模型实例中协调视觉和语言的生成。TextHarmony在视觉和语言模态之间实现更统一的生成过程。研究团队推出高质量的图像字幕数据集DetailedTextCaps-100K,基于高级闭源MLLM合成,进一步提升模型的视觉文本生成能力。

xAR 是字节跳动和约翰·霍普金斯大学联合提出的新型自回归视觉生成框架。框架通过“下一个X预测”(Next-X Prediction)和“噪声上下文学习”(Noisy Context Learning)技术,解决了传统自回归...

X-Dyna 是基于扩散模型的动画生成框架,基于驱动视频中的面部表情和身体动作,将单张人类图像动画化,生成具有真实感和环境感知能力的动态效果。核心是 Dynamics-Adapter 模块,能将参考图像的外观信息有效地整合到...
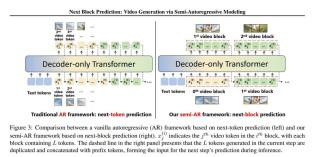
VideoWorld是北京交通大学、中国科学技术大学和字节跳动合作开展的一项研究项目,探索深度生成模型是否能仅通过未标注的视频数据学习复杂的知识,包括规则、推理和规划能力。...


UniTok 是字节跳动联合香港大学和华中科技大学推出的统一视觉分词器,能同时支持视觉生成和理解任务。基于多码本量化技术,将视觉特征分割成多个小块,每块用独立的子码本进行量化,极大地扩展离散分词的表示能力,解决传统分词器在细...


SeedEdit是字节跳动豆包大模型团队推出的通用图像编辑模型,基于简单的自然语言指令编辑图像,包括修图、换装、美化、风格转换及在指定区域添加或删除元素等。SeedEdit的核心优势为在维持原始图像和生成新图像之间找到最佳平...


PhotoDoodle是新加坡国立大学、上海交通大学、北京邮电大学、字节跳动和Tiamat团队联合推出的艺术化图像编辑框架,基于少量样本学习艺术家的独特风格,实现照片涂鸦(photo doodling)。PhotoDoodl...

MimicTalk是浙江大学和字节跳动共同研发推出的,基于NeRF(神经辐射场)技术,能在极短的时间内,仅需15分钟训练出个性化和富有表现力的3D说话人脸模型。MimicTalk提高了训练效率,基于高效的微调策略和具有上下文...

MMaDA(Multimodal Large Diffusion Language Models)是普林斯顿大学、清华大学、北京大学和字节跳动推出的多模态扩散模型,支持跨文本推理、多模态理解和文本到图像生成等多个领域实现卓越...
全部评论
留言在赶来的路上...
发表评论