

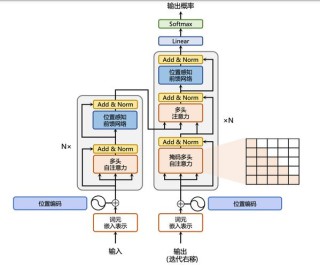
ViTPose 是基于 Transformer 架构的人体姿态估计模型。以普通视觉 Transformer 作为骨干网络,通过将输入图像切块并送入 Transformer block 来提取特征,再经解码器将特征解码为热图,实现对人体关键点的精准定位。ViTPose 系列模型具有多种规模版本,如 ViTPose-B、ViTPose-L、ViTPose-H 等,可根据不同需求选择。在 MS COCO 等数据集上表现出色,展现了简单视觉 Transformer 在姿态估计任务上的强大潜力。此外,ViTPose+ 作为改进版本,拓展到多种身体姿态估计任务,涵盖动物、人体等不同类型关键点,进一步提升了性能和适用范围。

(图片来源网络,侵删)

(图片来源网络,侵删)














全部评论
留言在赶来的路上...
发表评论