

VibeVoice 是微软推出的新型文本到语音(TTS)模型,能生成富有表现力、长篇幅、多说话者的对话式音频,如播客。模型通过创新的连续语音标记化技术和下一代标记扩散框架,结合大型语言模型(LLM),实现高效处理长序列音频的能力,同时保持高保真度。VibeVoice 能合成长达90分钟的语音,支持多达4位不同说话者,突破传统TTS系统的限制,为自然对话和情感表达提供新的可能。

(图片来源网络,侵删)

(图片来源网络,侵删)
VibeVoice 是微软推出的新型文本到语音(TTS)模型,能生成富有表现力、长篇幅、多说话者的对话式音频,如播客。模型通过创新的连续语音标记化技术和下一代标记扩散框架,结合大型语言模型(LLM),实现高效处理长序列音频的能力,同时保持高保真度。VibeVoice 能合成长达90分钟的语音,支持多达4位不同说话者,突破传统TTS系统的限制,为自然对话和情感表达提供新的可能。

UFO² 是微软推出的面向 Windows 桌面的多Agent操作系统(AgentOS),基于深度系统集成和自然语言交互实现复杂桌面任务的自动化。UFO²基于中央 HostAgent 分解任务协调多个应用专用的 AppAge...
TinyTroupe是microsoft推出的实验性Python库,用在模拟具有特定个性、兴趣和目标的人工代理(TinyPersons),在模拟环境(TinyWorld)中进行互动。TinyTroupe基于大型语言模型(如G...


Text-Diffuser 2是由来自微软研究院、香港科技大学和中山大学的研究人员最新推出的一个基于扩散模型的文本渲染方法,旨在解决图像扩散模型生成文字时在灵活性、自动化、布局预测能力和风格多样性方面的局限性,以提高生成图像...
TaskWeaver是由微软推出的一个代码优先的AI智能体框架,专注于无缝规划和执行数据分析任务。基于代码片段解释用户请求,高效协调各种插件(以函数形式)执行数据分析任务,支持状态化的执行方式。TaskWeaver支持丰富的...
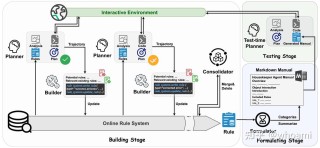
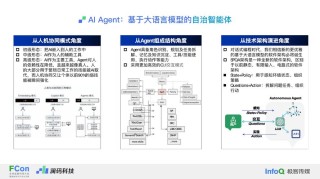
Phi-3是微软研究院推出的新一代系列先进的小语言模型,包括phi-3-mini、phi-3-small和phi-3-medium三个不同规模的版本。这些模型在保持较小的参数规模的同时,通过精心设计的训练数据集和优化的算法,...


NLWeb 是微软推出的开源项目,基于简化网站自然语言界面的创建,让任何网站都能变成 AI 驱动的应用程序。NLWeb用 Schema.org、RSS 等半结构化数据,结合 LLM 工具,为用户提供类似 AI 助手的交互体验...
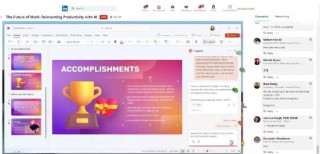
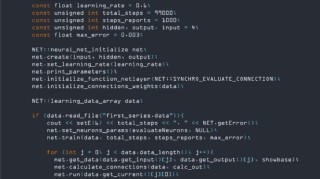
Mu是微软推出的小参数语言模型,仅3.3亿参数,支持在 NPU 和边缘设备上高效运行。模型基于编码器解码器架构,基于硬件感知优化、模型量化及特定任务微调,实现每秒超100 tokens的响应速度。...


LAM是微软推出的名为“Large Action Model”(简称 LAM)的新人工智能模型。与传统语言模型不同,LAM能够自主操作Windows程序,实现真实任务执行。 能理解文本,将用户请求转化为具体行动,如启动程序或...

全部评论
留言在赶来的路上...
发表评论