

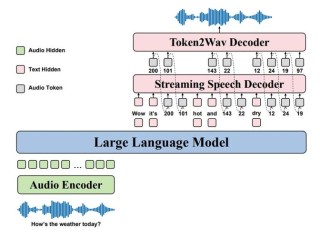
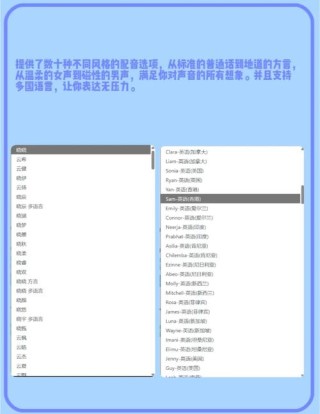
Voila 是开源的端到端语音大模型,专为语音交互而设计。具备高保真、低延迟的实时流式音频处理能力,能直接处理语音输入并生成语音输出,为用户提供流畅且自然的交互体验。Voila 集成了语音和语言建模能力,支持数百万种预构建和自定义声音,用户可以通过文本指令或音频样本轻松定制说话者的特征和声音。 包含两个主要模型:Voila-e2e 用于端到端语音对话,Voila-autonomous 用于自主互动。一个模型即可支持多种音频任务,降低了开发和部署成本。

(图片来源网络,侵删)

(图片来源网络,侵删)




全部评论
留言在赶来的路上...
发表评论