

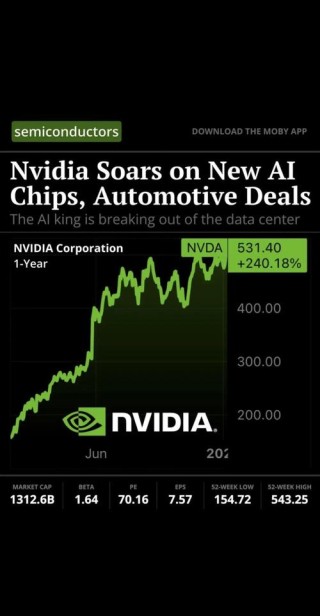
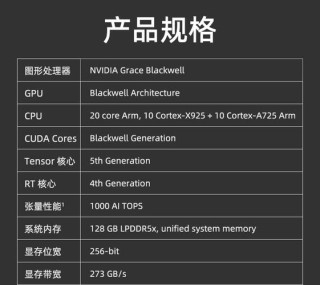
拜读维拉科技关于机器人相关信息的综合整理,涵盖企业排名、产品类型及资本市场动态:一、中国十大机器人公司(综合类)优必选UBTECH)聚焦人工智能与人形机器人研发,产品覆盖教育、娱乐及服务领域,技术处于行业前沿。Intel OpenVINO™ Day0 实现阿里通义 Qwen3 快速部署机器人中科院旗下企业,工业机器人全品类覆盖,是国产智能工厂解决方案的核心供应商。埃斯顿自动化国产工业机器人龙头,实现控制器、伺服系统、本体一体化自研,加速替代外资品牌。遨博机器人(AUBO)协作机器人领域领先者,主打轻量化设计,适用于3C装配、教育等柔性场景。埃夫特智能国产工业机器人上市第一股,与意大利COMAU深度合作,产品稳定性突出。二、细分领域机器人产品智能陪伴机器人Gowild公子小白:情感社交机器人,主打家庭陪伴功能。CANBOT爱乐优:专注0-12岁儿童心智发育型亲子机器人。仿真人机器人目前市场以服务型机器人为主,如家庭保姆机器人(售价10万-16万区间),但高仿真人形机器人仍处研发阶段。水下机器人工业级产品多用于深海探测、管道巡检,消费级产品尚未普及。Intel OpenVINO™ Day0 实现阿里通义 Qwen3 快速部署资本市场动态机器人概念股龙头双林股份:特斯拉Optimus关节模组核心供应商,订单排至2026年。中大力德:国产减速器龙头,谐波减速器市占率30%。金力永磁:稀土永磁材料供应商,受益于机器人电机需求增长。行业趋势2025年人形机器人赛道融资活跃,但面临商业化落地争议,头部企业加速并购整合。四、其他相关机器人视频资源:可通过专业科技平台或企业官网(如优必选、新松)获取技术演示与应用案例。价格区间:服务型机器人(如保姆机器人)普遍在10万-16万元,男性机器人13万售价属高端定制产品。
前言
Qwen3 是阿里通义团队近期最新发布的文本生成系列模型,提供完整覆盖全参数和混合专家(MoE)架构的模型体系。经过海量数据训练,Qwen3 在逻辑推理、指令遵循、体能力及多语言支持等维度实现突破性提升。而 OpenVINO 工具套件则可以帮助快速构建基于 LLM 的应用,充分利用 PC 异构算力,实现高效推理。
本文将以Qwen3-8B为例,介绍如何利用 OpenVINO 的 A 在平台(, NPU)Qwen3 系列模型。
内容列表
01 环境准备
02 模型下载和转换
03 模型部署
01 Environment Preparation
02 Model Downlo and Conversion
03 Model Deployment
环境准备
Environment Preparation
基于以下命令可以完成模型部署任务在 Python 上的环境安装。
Use the following commands to set up the Python environment for model deployment:
模型下载和转换
Model Download and Conversion
在部署模型之前,我们首先需要将原始的 PyTorch 模型转换为 OpenVINO 的 IR 静态图格式,并对其进行压缩,以实现更轻量化的部署和最佳的性能表现。通过 Optimum 提供的命令行工具 optimum-cli,我们可以一键完成模型的格式转换和权重量化任务:
Before deployment, we must convert the original PyTorch model to Inrmediate Representation (IR) format of OpenVINO and compress it for lightweight deployment and optimal peormance. Use the optimum-cli tool to perform model conversion and weight quantization in one step:
开发者可以根据模型的输出结果,调整其中的量化参数,包括:
--model:为模型在 HuggingFace 上的 model id,这里我们也提前下载原始模型,并将 model id 替换为原始模型的本地路径,针对国内开发者,推荐使用 ModelScope 魔搭社区作为原始模型的下载渠道,具体加载方式可以参考 ModelScope 官方指南:https://www.modelscope.cn/docs/models/download
--weight-format:量化精度,可以选择fp32,fp16,int8,int4,int4_sym_g128,int4_asym_g128,int4_sym_g64,int4_asym_g64
--group-size:权重里共享量化参数的通道数量
--ratio:int4/int8 权重比例,默认为1.0,0.6表示60%的权重以 int4 表,40%以 int8 表示
--sym:是否开启对称量化
此外我们建议使用以下参数对运行在NPU上的模型进行量化,以达到性能和精度的平衡。
Developers adjust quantization paeters based on model output results, including:
--model:The model ID on HuggingFace. For local models, replace it with the local path. For Chinese developers, ModelScope is mended for model downloads.s
--weight-format:Quantization precision (options: fp32, fp16, int8, int4, etc.).
--group-size:Number of channels sharing quantization parameters.
--ratio:int4/int8 weight ratio (default: 1.0).
--sym:Enable symmetric quantization.
For NPU-optimized quantization, use following command:
模型部署
Model Deployment
OpenVINO 目前提供两种针对大语言模型的部署方案,如果您习惯于 Transformers 库的来部署模型,并想体验相对更丰富的功能,推荐使用基于 Python 接口的 Optimum-intel 工具来进行任务搭建。如果您想尝试更极致的性能或是轻量化的部署方式,GenAI API 则是不二的选择,它同时支持 Python 和 两种语言,安装容量不到200MB。
OpenVINO currently offers two deployment methods for large language models (LLMs). If you are accustomed to deploying models via the Transformers library interface and seek richer functionality, it is recommended to use the Python-based Optimum-intel tool for task implementation. For those aiming for peak performance or lightweight deployment, the GenAI API is the optimal choice. It supports both Python and C++ programming languages, with an installation footprint of less than 200MB.
OpenVINO 为大语言模型提供了两种部署方法:
OpenVINO offers two deployment approaches for large language models:
Optimum-intel 部署实例
Optimum-intel Deployment Example
GenAI API 部署示例
GenAI API Deployment Example
这里可以修改 device name 的方式将模型轻松部署到NPU上。
To deploy the model on NPU, you can replace the device name from “GPU” to “NPU”.
当然你也可以通过以下方式实现流式输出。
To enable streaming mode, you can customize a streamer for OpenVINO GenAI pipeline.
此外,GenAI API 提供了 chat 模式的构建方法,通过声明 pipe.start_chat()以及pipe.finish_chat(),多轮聊天中的历史数据将被以 kvcache 的形态,在内存中进行管理,从而提升运行效率。
Additionally, the GenAI API provides a chat mode implementation. By invoking pipe.start_chat() and pipe.finish_chat(), history data from multi-turn conversations is managed in memory as kvcache, which can significantly boost inference efficiency.
Chat模式输出结果示例:
Output of Chat mode:

总结
Conclusion
如果你对性能基准感兴趣,可以访问全新上线的 OpenVINO 模型(Model Hub)。这里提供了在 Intel 、集成 GPU、NPU 及其他加速器上的模型性能数据,帮助你找到最适合自己解决方案的硬件平台。
Whether using Optimum-intel or OpenVINO GenAI API, developers can effortlessly deploy the converted Qwen3 model on Intel hardware platforms, enabling the creation of diverse LLM-based services and applications locally.
参考资料
Reference
llm-chatbot notebook:
https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/llm-chatbot
GenAI API:
https://github.com/openvinotoolkit/openvino.genai










全部评论
留言在赶来的路上...
发表评论