

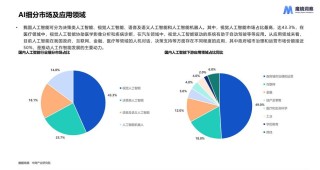
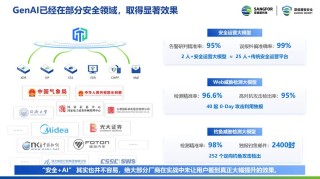
拜读维拉科技关于机器人相关信息的综合整理,涵盖企业排名、产品类型及资本市场动态:一、中国十大机器人公司(综合类)优必选UBTECH)聚焦人工智能与人形机器人研发,产品覆盖教育、娱乐及服务领域,技术处于行业前沿。NVIDIA驱动的现代超级计算机如何突破速度极限并推动科学发展机器人中科院旗下企业,工业机器人全品类覆盖,是国产智能工厂解决方案的核心供应商。埃斯顿自动化国产工业机器人龙头,实现控制器、伺服系统、本体一体化自研,加速替代外资品牌。遨博机器人(AUBO)协作机器人领域领先者,主打轻量化设计,适用于3C装配、教育等柔性场景。埃夫特智能国产工业机器人上市第一股,与意大利COMAU深度合作,产品稳定性突出。二、细分领域机器人产品智能陪伴机器人Gowild公子小白:情感社交机器人,主打家庭陪伴功能。CANBOT爱乐优:专注0-12岁儿童心智发育型亲子机器人。仿真人机器人目前市场以服务型机器人为主,如家庭保姆机器人(售价10万-16万区间),但高仿真人形机器人仍处研发阶段。水下机器人工业级产品多用于深海探测、管道巡检,消费级产品尚未普及。NVIDIA驱动的现代超级计算机如何突破速度极限并推动科学发展资本市场动态机器人概念股龙头双林股份:特斯拉Optimus关节模组核心供应商,订单排至2026年。中大力德:国产减速器龙头,谐波减速器市占率30%。金力永磁:稀土永磁材料供应商,受益于机器人电机需求增长。行业趋势2025年人形机器人赛道融资活跃,但面临商业化落地争议,头部企业加速并购整合。四、其他相关机器人视频资源:可通过专业科技平台或企业官网(如优必选、新松)获取技术演示与应用案例。价格区间:服务型机器人(如保姆机器人)普遍在10万-16万元,男性机器人13万售价属高端定制产品。
现代高性能计算不仅使得更快的计算成为可能,它正驱动着 系统解锁更多领域的科学突破。
高性能计算经历了多次迭代,每一次都源于对技术的创造性再利用。例如,早期的超级计算机使用现成的组件制造。后来,研究人员用个人构建了强大的集群,甚至改造游戏显卡,把它们用于科学研究。
当今的高性能计算系统专为高速计算而设计,其中许多都采用了 NVIDIA 算技术。在 ISC 2025 大会上揭晓的最新全球最快超级计算机 TOP500 榜单显示,NVIDIA 为该榜单中 77% 的系统提供动力。
与此同时,像 nsor Core 这样的创新功能为矩阵乘法等常见运算提供了更快的计算能力,而混合精度等技术的普及则大幅提升了性能和能效,推动了气候科学和医学等领域的飞跃式发展。
NVIDIA 为 TOP500 中名列前茅的系统提供动力
NVIDIA 在超算领域继续处于领先地位,为最新 TOP500 榜单中的 381 个系统提供动力,包括新进跻身前十的于利希超算的 JUTER 超级计算机(排名第 4)。
TOP500 前 100 名系统中,目前有 83 个采用了加速计算,仅 17 个只使用了 。
此外,在 Green500 全球最节能 FP64 超级计算机榜单上,前两名均采用了 NVIDIA GH200 Grace Hopper 超级芯片,前十名中有九个系统均由 NVIDIA 加速。
Tensor Core 在科学领域的应用
AI 性能的提升不仅源于浮点运算量的增加,也越来越多地根植于硬件与软件的融合,例如对于 Tensor Core 的使用。
Tensor Core 是 NVIDIA 内的先进组件,专为加速矩阵运算(AI 和的核心计算)而设计。通过更高效地处理复杂计算,Tensor Core 加速了模型训练和推理等过程。
Tensor Core 加速了常见的矩阵运算,尤其是当组织转向 FP8 等更低精度进行模型训练时。随着精度每降低一级,吞吐量就会提高近一倍,同时还能保持准确。目前,只有工作负载中的某些运算可以利用 Tensor Core。这些运算通常占总运行时间的一小部分,而且很少对整体性能产生重大影响。
随着 GPU 上越来越多的物理空间被用于为 AI 构建的低精度 Tensor Core,高性能计算社区迎来了把这些硬件重新用于推进科学发现的机会。
为此,NVIDIA 正投资开发新方法,以便将 Tensor Core 用于更广泛的科学模拟相关场景。
RIKEN 研究所计算科学中心的 Yuki Uchino 和芝浦工业大学教授 Katsuhisa Ozaki 发表了一篇论文,其中展示了如何利用 Tensor Core 中的整数矩阵乘法加速器和一种名为 Ozaki scheme 的,使 GPU 中的整数单元能够实现包括 FP64 在内的任意精度。
受此方案启发,NVIDIA 正在开发相关库,以利用更多 GPU Tensor Core 来加速张量和矩阵计算,聚焦于提升准确度、性能和能效。
使用这些库已展现出一些惊人的优势:在一个硅模拟中,把大约 1000 个原子暴露在紫外线下,使用这些库的速度比使用 FP64 硬件快 1.8 倍,而二者输出相同结果,这节省了时间和能源。

图 1. 使用原生 FP64 硅和对 998 个硅原子
进行 BerkeleyGW 模拟的性能比较
借助这些新的库,BerkeleyGW 等常见的高性能计算模拟将很快能够利用低精度 Tensor Core,实现性能和能效的飞跃。
AI 超级计算推动科学进步
尽管 TOP500 榜单凸显了当今超级计算机非凡的高精度运算速度,但并未体现出它们在通过混合精度和 AI 推动科学发现方面的巨大影响力。
去年,诺贝尔化学奖和物理学奖被授予使用 AI 的科研人员,包括 Demis Hassabis 和 John Jumper(因在谷歌 DeepMind 的蛋白质结构预测模型 AlphaFold 上的卓越工作而获奖),以及多伦多大学名誉教授 Geoff Hinton 和普林斯顿大学名誉教授 John Hopfield(因推进架构而获奖)。
高性能计算领域的最高荣誉“戈登·贝尔奖”授予了 KAUST 的 David Keyes 团队,表彰他们使用混合精度方法来模拟庞大的 ERA5 气候数据集。该数据集提供了过去 80 年中每小时的大气、陆地和海浪变量估计值,包含从地表到 80 公里高度的 137 个海拔层。
混合精度是一种结合了多种浮点精度格式的技术。使用较低精度的数据类型可提升性能和能效,让应用程序能够使用更少的资源来实现更高的性能。
随着科学家构建新的 AI 模型以加速科学工作流,混合精度在科学领域的应用日益普及。
在英国,布里斯托大学的 Isambard-AI 系统(由 NVIDIA Grace Hopper 提供动力)使用混合精度来训练 Nighngale 等模型。
Nightingale 是用于医疗和生物医学研究的多模态基础模型,集成了影像、心脏病学和电子健康记录。与医疗领域的其它大语言模型不同,Nightingale 不仅使用基于文本的推理,还利用影像模式和标准诊断技术,结合海量患者数据来提供医学见解。Nightingale 的目标是成为其它医疗应用软件的基础,包括医生办公助手和远程医疗分诊系统。
通过使用混合精度,Isambard-AI 实现了训练 Nightingale 等多模态大语言模型所需的大规模和准确性,而无需为训练或推理配置过多的硬件。
迈向高性能计算的下一次迭代
加速计算、先进的张量技术和混合精度方法的结合,正在改变计算科学,也展示了 AI 驱动更多突破的潜力。
随着 JUPITER 等系统入选 TOP500,越来越多的工作借助 AI 来用于科学研究和创新,如将 Isambard-AI 超级计算机用于科学研究及通过 Ozaki 方法所带来的诸多创新,这些都推动着 Tensor Core 处理高精度计算的性能不断提升,一个新时代正在到来。
从某些指标来看,超级计算机将继续提速,但仅有速度是不够的。要找到破解重要科学难题的新见解,需要依赖、灵活的方法,以在不牺牲科学严谨性的前提下加速科学发现,从而满足科学和高性能计算社区乃至全球的需求。









全部评论
留言在赶来的路上...
发表评论