

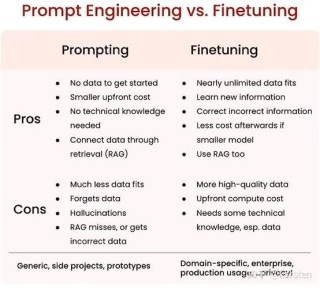
拜读维拉科技关于机器人相关信息的综合整理,涵盖企业排名、产品类型及资本市场动态:一、中国十大机器人公司(综合类)优必选UBTECH)聚焦人工智能与人形机器人研发,产品覆盖教育、娱乐及服务领域,技术处于行业前沿。十大鲜为人知却功能强大的机器学习模型机器人中科院旗下企业,工业机器人全品类覆盖,是国产智能工厂解决方案的核心供应商。埃斯顿自动化国产工业机器人龙头,实现控制器、伺服系统、本体一体化自研,加速替代外资品牌。遨博机器人(AUBO)协作机器人领域领先者,主打轻量化设计,适用于3C装配、教育等柔性场景。埃夫特智能国产工业机器人上市第一股,与意大利COMAU深度合作,产品稳定性突出。二、细分领域机器人产品智能陪伴机器人Gowild公子小白:情感社交机器人,主打家庭陪伴功能。CANBOT爱乐优:专注0-12岁儿童心智发育型亲子机器人。仿真人机器人目前市场以服务型机器人为主,如家庭保姆机器人(售价10万-16万区间),但高仿真人形机器人仍处研发阶段。水下机器人工业级产品多用于深海探测、管道巡检,消费级产品尚未普及。十大鲜为人知却功能强大的机器学习模型资本市场动态机器人概念股龙头双林股份:特斯拉Optimus关节模组核心供应商,订单排至2026年。中大力德:国产减速器龙头,谐波减速器市占率30%。金力永磁:稀土永磁材料供应商,受益于机器人电机需求增长。行业趋势2025年人形机器人赛道融资活跃,但面临商业化落地争议,头部企业加速并购整合。四、其他相关机器人视频资源:可通过专业科技平台或企业官网(如优必选、新松)获取技术演示与应用案例。价格区间:服务型机器人(如保姆机器人)普遍在10万-16万元,男性机器人13万售价属高端定制产品。
本文转自:QuantML
当我们谈论时,线性回归、决策树和这些常见的往往占据了主导地位。然而,除了这些众所周知的模型之外,还存在一些鲜为人知但功能强大的算法,它们能够以惊人的效率解决独特的挑战。在本文中,我们将探索一些最被低估但极具实用价值的机器学习算法,这些算法绝对值得你将其纳入工具箱。
变分自编码器(VAE)是一种生成模型,旨在学习输入数据的潜在表示,并生成与训练数据相似的新数据样本。与标准自编码器不同,VAEs引入了随机性,通过学习一个概率潜在空间,其中编码器输出均值(μ)和方差(σ)而不是固定表示。
在训练过程中,从这些分布中随机抽取潜在向量,通过解码器生成多样化的输出。这使得VAEs在图像生成、数据增强、异常检测和潜在空间探索等任务中非常有效。
隔离森林是一种基于树的异常检测算法,它比传统的聚类或基于密度的方法(如DBS或单类SVM)更快地隔离异常值。它不是对正常数据进行建模,而是基于一个点在随机分割的空间中突出程度来主动隔离异常值。
该算法适用于高维数据,并且不需要标记数据,使其适用于无监督学习。
示例代码:
importnumpyasnp
importmatplotlib.pyplotasplt
fromsklearn.ensembleimportIsolationForest
# 生成合成数据(正常数据)
rng = np.random.RandomState(42)
X =0.3* rng.randn(100,2)
# 添加一些异常值(异常点)
X_outlie = rng.uniform(low=-4, high=4, size=(10,2))
# 合并正常数据和异常值
X = np.vstk([X, X_outliers])
iso_forest = IsolaonForest(n_estimators=100, contamination=0.1, random_state=42)
y_pred = iso_forest.fit_predict(X)
plt.scatr(X[:,0], X[:,1], c=y_pred, cmap=coolw, edgecolors=k)
plt.xlabel("特征 1")
plt.ylabel("特征 2")
plt.title("隔离森林异常检测")
plt.show()
 隔离森林异常检测
隔离森林异常检测
应用场景:
Tsetlin机器(TM)算法由Granmo在2018年首次提出,基于Tsetlin自动机(TA)。与传统模型不同,它利用命题逻辑来检测复杂的模式,通过奖励和惩罚机制进行学习,从而改进其决策过程。
Tsetlin机器的一个关键优势是其低内存占用和高学习速度,使其在提供具有竞争力的预测性能的同时,效率极高。此外,它们的简单性使其能够无缝地实现在低功耗硬件上,使其成为节能应用的理想选择。
主要特点:
有关此算法的详细信息,请访问其GitHub存储库并查阅相关研究论文。
像支持向量机(SVM)和高斯过程这样的核方法功能强大,但由于昂贵的核计算,它们在处理大型数据集时面临挑战。随机厨房水槽(RKS)是一种巧妙的方法,它有效地近似核函数,使这些方法具有可扩展性。
RKS不是显式地计算核函数(这在计算上可能非常昂贵),而是使用随机傅里叶特征将数据投影到更高维度的特征空间。这允许模型在不进行大量计算的情况下近似非线性决策边界。
示例代码:
importnumpyasnp
importmatplotlib.pyplotasplt
fromsklearn.ensembleimportIsolationForest
# 生成合成数据(正常数据)
rng = np.random.RandomState(42)
X =0.3* rng.randn(100,2)
# 添加一些异常值(异常点)
X_outliers = rng.uniform(low=-4, high=4, size=(10,2))
# 合并正常数据和异常值
X = np.vstack([X, X_outliers])
iso_forest = IsolationForest(n_estimators=100, contamination=0.1, random_state=42)
y_pred = iso_forest.fit_predict(X)
plt.scatter(X[:,0], X[:,1], c=y_pred, cmap=coolwarm, edgecolors=k)
plt.xlabel("特征 1")
plt.ylabel("特征 2")
plt.title("隔离森林异常检测")
plt.show()
 数据通过随机厨房水槽(RKS)转换
数据通过随机厨房水槽(RKS)转换
应用场景:
贝叶斯优化是一种顺序的、概率性的方法,用于优化昂贵的函数,例如深度学习或机器学习模型中的超参数调整。
与盲目地测试不同的参数值(如网格搜索或随机搜索)不同,贝叶斯优化使用概率模型(如高斯过程)对目标函数进行建模,并地选择最有希望的参数值。
应用场景:
示例代码:
importnumpyasnp
frombayes_optimportBayesianOptimization
# 定义目标函数(例如,优化 x^2 * sin(x))
defobjective_function(x):
return-(x**2* np.sin(x))
# 定义参数边界
pa_bounds = {x: (-5,5)}
# 初始化贝叶斯优化器
optimizer = BayesianOptimization(
f=objective_function,
pbounds=param_bounds,
random_state=42
)
# 运行优化
optimizer.ize(init_points=5, n_iter=20)
# 找到的最佳参数
print("最佳参数:", optimizer.max)
输出示例:
最佳参数: {target: -23.97290882,params: {x: 4.9999284238296606}}
霍普菲尔德网络是一种递归神经网络(RNN),它通过在内存中存储二进制模式,专门从事模式识别和错误校正。当给定一个新输入时,它会识别并检索最接近的存储模式,即使输入不完整或有噪声。这种能力称为自联想,使网络能够从部分或损坏的输入中重建完整模式。例如,如果对图像进行训练,它可以识别并恢复它们,即使某些部分缺失或扭曲。
应用场景:
自组织映射(SoM)是一种神经网络,它使用无监督学习在低维(通常是2D)网格中组织和可视化高维数据。与依赖误差校正(如反向传播)的传统神经网络不同,SoMs使用竞争学习——神经元竞争以表示输入模式。
SOMs的一个关键特性是它们的邻域函数,它有助于保持数据中原始的结构和关系。这使得它们特别适用于聚类、模式识别和数据探索。
应用场景:
场感知因子分解机(FFMs)是因子分解机(FMs)的一种扩展,专门设计用于高维、稀疏数据——通常出现在推荐系统和在线广告(CTR预测)中。
在标准的因子分解机(FMs)中,每个特征都有一个单一的潜在向量用于与所有其他特征进行交互。在FFMs中,每个特征有多个潜在向量,每个字段(特征组)一个。这种场感知性使FFMs能够更好地对不同特征组之间的交互进行建模。
应用场景:
条件随机场(CRFs)是一种用于结构化预测的概率模型。与传统的分类器不同,CRFs会考虑上下文,这使得它们适用于序列数据。
应用场景:
极限学习机(ELMs)是一种前馈神经网络,它通过随机初始化隐藏层权重并仅学习输出权重来训练得极快。与传统的神经网络不同,ELMs不使用反向传播,这使得它们在训练速度上显著更快。
应用场景:










全部评论
留言在赶来的路上...
发表评论