


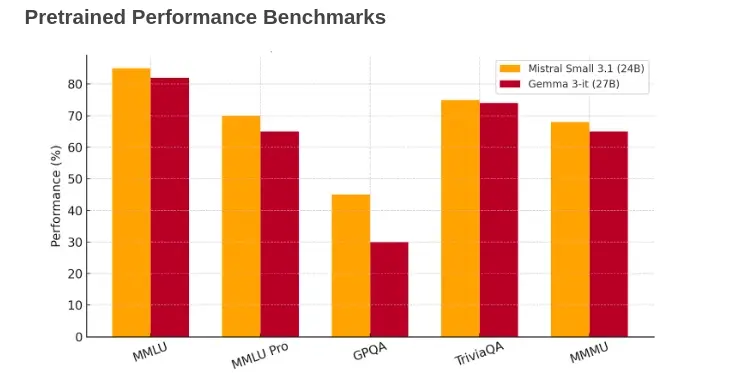
以下是 DeepSeek-V3 0324 和 Claude-Sonnet 3.7 的基准测试结果明细:
DeepSeek V3 0324: 81.2% | Claude 3.7 Sonnet: 75.9%
分析:DeepSeek V3 0324 在处理多任务语言理解和复杂推理方面表现出更强的能力,得分高于 Claude 3.7 Sonnet。
DeepSeek V3 0324: 86.1% | Claude 3.7 Sonnet: 80.7%
分析:DeepSeek V3 0324 在回答复杂的常识和推理问题方面再次胜过 Claude 3.7 Sonnet,展示了更好的答题能力。
DeepSeek V3 0324: 68.4% | Claude 3.7 Sonnet: 60.1%
分析:与 Claude 3.7 Sonnet 相比,DeepSeek V3 0324 在数学问题解决方面得分更高,表明其在解决各种数学相关任务方面的能力更强。
DeepSeek V3 0324: 94.0% | Claude 3.7 Sonnet: 82.2%
分析:DeepSeek V3 0324在高级推理任务中表现出色,在更复杂的多步骤任务中明显优于Claude 3.7 Sonnet。
DeepSeek V3 0324: 90.2% | Claude 3.7 Sonnet: 82.6%
分析:DeepSeek V3 0324 在编码和软件开发任务中得分更高,反映出它对实时编程、调试和编码挑战有更好的理解。
DeepSeek V3-0324 以其准确性、高效率和强大的执行力在多项任务中脱颖而出。它能确保编码挑战、动画和游戏逻辑的功能正确无误,因此在实际应用中非常可靠。Claude 3.7 虽然结构合理、可读性强,但在执行方面存在缺陷,影响了可用性。DeepSeek V3-0324 卓越的优化和完善的输出使其成为注重性能和正确性的开发人员的首选。与此同时,Claude 3.7 对那些重视代码的简洁性和可维护性的人来说仍然非常有用。





全部评论
留言在赶来的路上...
发表评论