


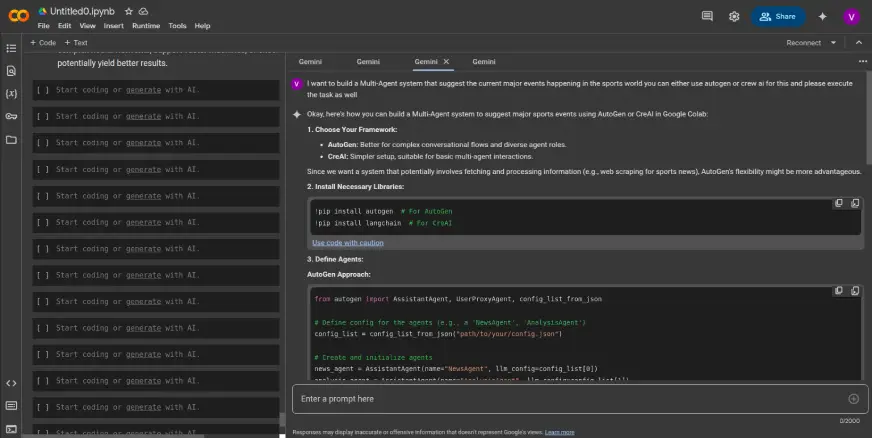
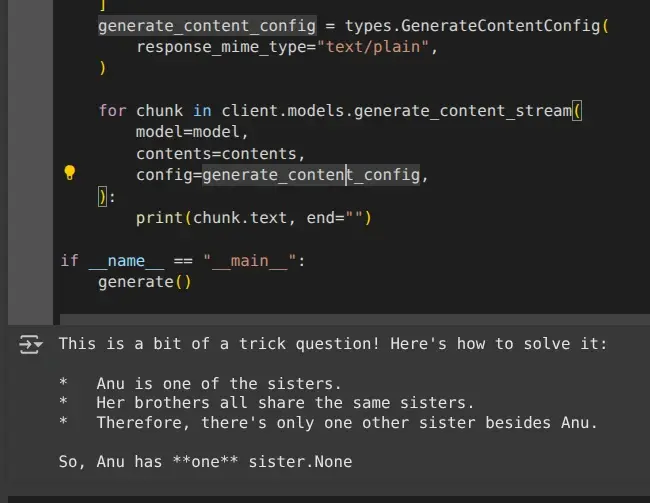
通过简单的 API 调用,Google Gemini for Computer Vision 可以轻松完成对象检测、图像字幕和 OCR 等任务。通过发送图像和清晰的文字说明,你可以引导模型理解并获得可用的实时结果。
虽然 Gemini 非常适合通用任务或快速实验,但它并不总是最适合高度专业化的用例。假设你正在处理小众对象,或者需要更严格地控制精度。在这种情况下,传统的方法仍然有效:收集数据集,使用 YOLO 标签器等工具对其进行标注,然后根据自己的需要训练一个自定义模型。
通过简单的 API 调用,Google Gemini for Computer Vision 可以轻松完成对象检测、图像字幕和 OCR 等任务。通过发送图像和清晰的文字说明,你可以引导模型理解并获得可用的实时结果。
虽然 Gemini 非常适合通用任务或快速实验,但它并不总是最适合高度专业化的用例。假设你正在处理小众对象,或者需要更严格地控制精度。在这种情况下,传统的方法仍然有效:收集数据集,使用 YOLO 标签器等工具对其进行标注,然后根据自己的需要训练一个自定义模型。

...

...
...
全部评论
留言在赶来的路上...
发表评论