

? 第1张")
分析:
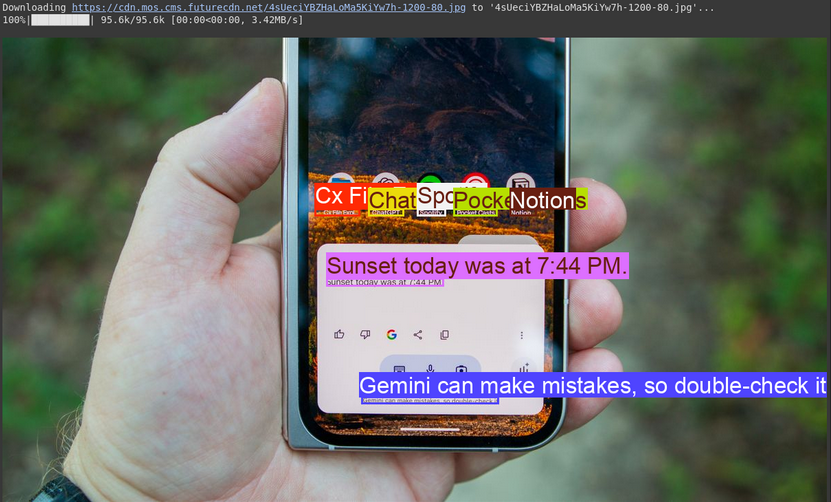
数据科学代理在执行这项任务时遇到了困难,因为它是为处理数据集而不是实时数据而设计的。构建多代理系统需要实时数据,而不仅仅是静态文件,因此代理无法独立完成这项任务。相反,它提供了一个现成的代码片段,用户必须自己运行和测试。这显示了一个明显的局限–它擅长数据分析、模型训练和处理结构化数据,但在实时数据、应用程序接口或构建可自行运行的系统方面却不尽如人意。它提供的代码是一个有益的开端,但用户仍然需要运行它并手动修复任何问题。
虽然数据科学代理在处理结构化数据集方面表现出色,但它无法处理 TXT、PDF、图像和 JSON 等非结构化格式,这限制了它的应用范围。为使其更适合生成式人工智能任务,未来的改进措施包括
通过整合这些功能,数据科学代理可以发展成为一个全面的人工智能助手,弥合结构化和非结构化数据处理之间的差距,同时扩大其在生成式人工智能驱动的工作流程中的作用。
谷歌 Colab 中的数据科学代理是一款人工智能助手,能让数据分析、模型构建和优化变得更简单。它擅长处理 CSV 或 XLS 文件等结构化数据,并为你提供清晰的分步流程。它甚至还能为你修复错误。它与 TensorFlow 和 PyTorch 协作得很好,因此构建神经网络或 LSTM 等更加简单。但是,它在处理文本文件、PDF、JSON 或图像等非结构化数据时很吃力,这限制了它的功能。如果它将来能处理这些数据,再加上能理解文档和处理实时数据,那么它将为数据科学家和人工智能研究人员提供更大的帮助。



全部评论
留言在赶来的路上...
发表评论