

AndroidGen 是智谱技术团队推出增强基于大语言模型(LLM)的 Agent 能力的框架,特别是在数据稀缺的情况下。框架通过收集人类任务轨迹基于这些轨迹训练语言模型,开发出无需人工标注轨迹的 Agent,显著提升 LLM 执行复杂任务的能力。

(图片来源网络,侵删)

(图片来源网络,侵删)
AndroidGen 是智谱技术团队推出增强基于大语言模型(LLM)的 Agent 能力的框架,特别是在数据稀缺的情况下。框架通过收集人类任务轨迹基于这些轨迹训练语言模型,开发出无需人工标注轨迹的 Agent,显著提升 LLM 执行复杂任务的能力。

AuraFusion360是用于360°无边界场景修复的新型基于参考的方法,主要用于虚拟现实和建筑可视化等领域的三维场景修复。通过高斯散射表示的3D场景,实现了高质量的物体去除和孔洞填充。...
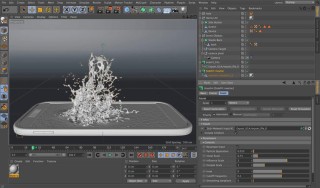
AuraFlow v0.1是Fal团队推出的开源AI文生图模型,拥有6.8B参数量。优化了MMDiT架构,提升了模型的计算效率和可扩展性。AuraFlow擅长精准图像生成,尤其在物体空间构成和色彩表现上表现突出,在人物生成上...
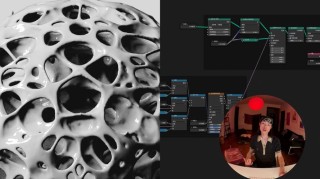
Augmented Physics是一个创新的教育工具,基于集成机器学习技术,将物理教科书中的静态图表转换成互动式和嵌入式的物理模拟。工具基于先进的计算机视觉技术,比如Segment Anything和多模态大型语言模型(L...
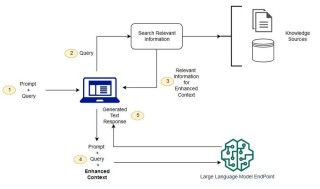
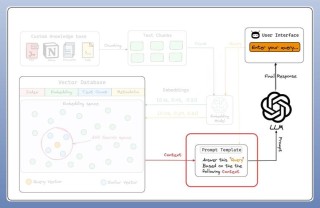
AudioX 是香港科技大学和月之暗面联合提出的统一扩散变压器模型,专门用于从任意内容生成音频和音乐。模型能处理多种输入模态,包括文本、视频、图像、音乐和音频,生成高质量的音频输出。...


AudioGenie是腾讯AI Lab团队推出的多模态音频生成工具,能从视频、文本、图像等多种模态输入生成音效、语音、音乐等多种音频输出。工具采用无训练的多智能体框架,通过生成团队和监督团队的双层架构实现高效协同。...
AudioGen-Omni是快手推出的多模态音频生成框架,框架能基于视频、文本等输入生成高质量的音频、语音和歌曲。框架通过统一的歌词-文本编码器和相位对齐各向异性位置注入(PAAPI)技术,实现精准的视听对齐和跨模态同步。...


Audio-SDS是NVIDIA AI研究团队推出的创新技术,将Score Distillation Sampling(SDS)技术扩展至文本条件音频扩散模型,为音频处理领域带来了重大突破。无需重新训练模型,可将任意预训练音...

Audio Decomposition是音频处理技术,基于傅里叶变换和信封匹配将音乐中的各个音符和乐器分离,实现音乐到乐谱的转换。Audio Decomposition开源项目是Matthew Bird推出的,无需外部乐器分...

全部评论
留言在赶来的路上...
发表评论