

DeepSeek R1-Zero 是 团队开发的完全依赖纯强化学习(RL)训练的推理模型,未使用任何监督微调(SFT)数据。在推理任务上表现出色,在 AIME 2024 数学竞赛中,其 pass@1 分数从 15.6% 提升至 71.0%,接近 OpenAI-o1-0912 的水平。模型在训练过程中展现了自我进化能力,例如反思和重新评估解题方法。

(图片来源网络,侵删)

(图片来源网络,侵删)
DeepSeek R1-Zero 是 团队开发的完全依赖纯强化学习(RL)训练的推理模型,未使用任何监督微调(SFT)数据。在推理任务上表现出色,在 AIME 2024 数学竞赛中,其 pass@1 分数从 15.6% 提升至 71.0%,接近 OpenAI-o1-0912 的水平。模型在训练过程中展现了自我进化能力,例如反思和重新评估解题方法。

FLUX.1 Kontext 是由 Black Forest Labs 推出的图像生成与编辑模型,支持上下文感知的图像处理。模型基于文本和图像提示进行生成与编辑,支持对象修改、风格转换、背景替换、角色一致性保持和文本编辑等多...
FLUX-Text 是阿里推出的新型的多语言场景文本编辑框架,基于扩散模型(Diffusion Model)和轻量级字形嵌入模块。框架基于注入字形条件信息,提升复杂场景下文本生成的准确性和保真度,在处理非拉丁字符(如中文)时...
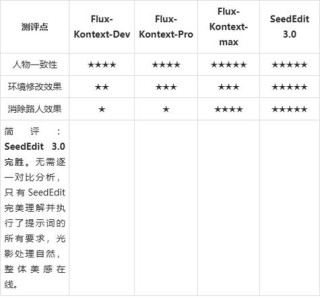
...

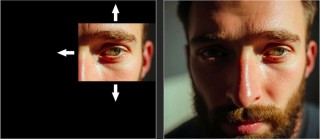
FLUX Tools是黑森林实验室推出的一套模型工具,能增强基础文本到图像模型FLUX.1的控制性和可操作性。FLUX Tools包括FLUX.1 Fill(图像修复和扩展)、FLUX.1 Depth(基于深度图的结构引导)...

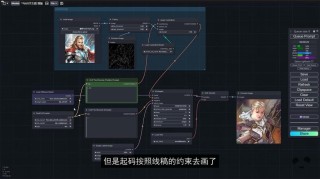
FLOAT是DeepBrain AI 和韩国先进科技研究院推出的音频驱动说话人头像生成模型,基于流匹配生成模型,学习运动潜在空间实现高效的时间一致性运动设计。模型基于Transformer架构的向量场预测器,实现帧间时间一致...
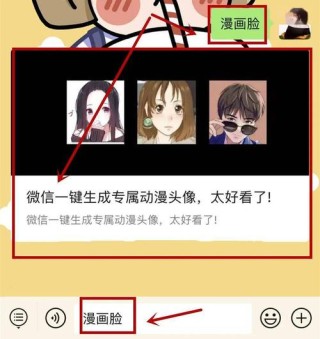

FACTS Grounding是谷歌DeepMind推出的评估大型语言模型(LLMs)能力的基准测试,衡量模型根据给定上下文生成事实准确且无捏造信息的文本的能力。FACTS Grounding测试集包含1719个跨多个领域的...
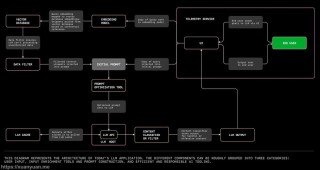

F5-TTS是由上海交通大学开源的一款高性能文本到语音(TTS)系统,基于流匹配的非自回归生成方法,结合扩散变换器(DiT)技术。系统在没有额外监督的情况下,基于零样本学习快速生成自然、流畅且忠实于原文的语音。...


F-Lite是Freepik团队联合FAL开源的10B参数的文生图模型。基于Freepik内部80M有版权的数据集训练,支持商业用途。F-Lite将T5-XXL作为文本编码器,基于抽取第17层特征注入到DiT模型中。...
全部评论
留言在赶来的路上...
发表评论