

FLOAT是DeepBrain AI 和韩国先进科技研究院推出的音频驱动说话人头像生成模型,基于流匹配生成模型,学习运动潜在空间实现高效的时间一致性运动设计。模型基于Transformer架构的向量场预测器,实现帧间时间一致性,支持语音驱动的情感增强,让生成的说话动作更自然、富有表现力。FLOAT在视觉质量、运动保真度和生成效率方面均超越现有的基于扩散和非扩散的方法,达到业界领先水平。

(图片来源网络,侵删)

(图片来源网络,侵删)
FLOAT是DeepBrain AI 和韩国先进科技研究院推出的音频驱动说话人头像生成模型,基于流匹配生成模型,学习运动潜在空间实现高效的时间一致性运动设计。模型基于Transformer架构的向量场预测器,实现帧间时间一致性,支持语音驱动的情感增强,让生成的说话动作更自然、富有表现力。FLOAT在视觉质量、运动保真度和生成效率方面均超越现有的基于扩散和非扩散的方法,达到业界领先水平。

FlowGram是字节跳动开源的基于节点编辑的可视化工作流搭建引擎,帮助开发者快速构建固定布局或自由连线布局的工作流。支持两种布局模式:固定布局适合顺序工作流和决策树,提供层次化结构和灵活的分支、复合节点;自由布局支持节点自...

FlowDirector是西湖大学AGI Lab团队联合中南大学推出的新型无训练(training-free)视频编辑框架,专门用在根据自然语言指令对视频内容进行精确编辑。框架直接在数据空间中建模编辑过程,用常微分方程(OD...
Florence-VL是创新的多模态大型语言模型(MLLMs),是马里兰大学和微软研究院共同推出的。Florence-VL用生成式视觉基础模型Florence-2丰富视觉表示,能捕捉图像的不同层次和方面的视觉特征,适应多样的...
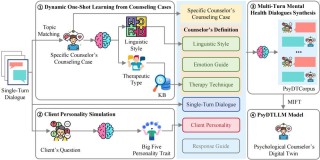
Florence-2 是微软 Azure AI 团队推出的多功能视觉模型,能执行图像描述、目标检测、视觉定位和图像分割等多种计算机视觉任务。Florence-2 基于 Transformer 架构,用序列到序列学习方法,编码...
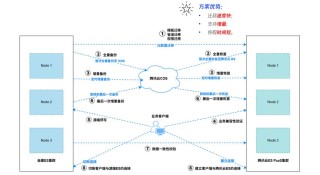
FlipSketch 是萨里大学推出的创新系统,能将静态绘图转变为文本引导的草图动画。技术基于三个关键创新实现:微调草图风格的帧生成、用噪声细化保持输入草图视觉完整性的参考帧机制,及在不失去视觉一致性的情况下实现流畅运动的双...

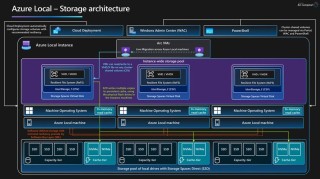
FlexiAct是清华大学和腾讯ARC实验室联合推出的新型动作迁移模型。FlexiAct能在给定目标图像的情况下,将参考视频中的动作迁移到目标主体上,在空间结构差异较大或跨域的异构场景中,实现精准的动作适配与外观一致性。...

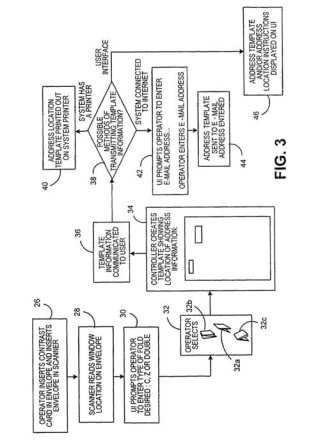
FlexTok 是瑞士洛桑联邦理工学院(EPFL)和苹果公司联合开发的图像处理技术。通过将二维图像重新采样为一维离散标记序列(token sequences),以灵活的长度描述图像,实现高效的图像压缩和生成。...
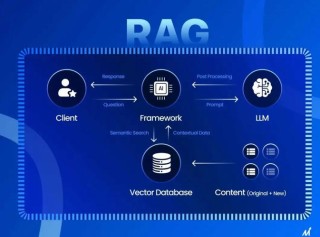
FlexRAG 是创新的检索增强生成(RAG)框架,解决传统 RAG 系统在处理长上下文时面临的计算成本高和生成质量不足的问题。通过将检索到的上下文信息压缩成紧凑的嵌入表示,显著降低计算负担。...
全部评论
留言在赶来的路上...
发表评论