

DeepSeek-GRM是和清华大学研究者共同提出的通用奖励模型(Generalist Reward Modeling)。通过点式生成式奖励建模(Pointwise Generative Reward Modeling, GRM)和自我原则点评调优(Self-Principled Critique Tuning, SPCT)等技术,显著提升了奖励模型的质量和推理时的可扩展性。GRM通过生成结构化的评价文本(包括评价原则和对回答的详细分析)来输出奖励分数,不是直接输出单一的标量值。DeepSeek-GRM在多个综合奖励模型基准测试中表现优异,显著优于现有方法和多个公开模型。推理时扩展性能尤为突出,随着采样次数增加,性能持续提升。

(图片来源网络,侵删)

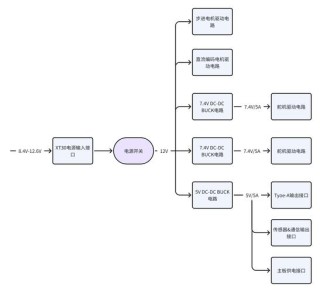
(图片来源网络,侵删)







全部评论
留言在赶来的路上...
发表评论