

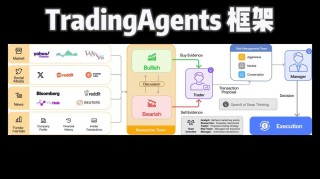
DiT(Diffusion Transformers)是一种新型的扩散模型,由William Peebles(Sora的研发负责人之一) 与纽约大学助理教授谢赛宁提出,结合了去噪扩散概率模型(DDPMs)和Transformer架构。扩散模型是一种生成模型,通过模拟数据的逐步去噪过程来生成新的样本。DiT的核心思想是使用Transformer作为扩散模型的骨干网络,而不是传统的卷积神经网络(如U-Net),以处理图像的潜在表示。近期伴随OpenAI视频生成模型的大热,DiT被视为Sora背后的技术基础之一而广受关注。
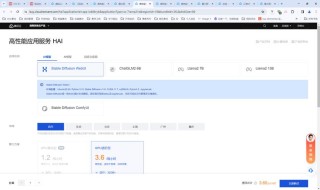
在DiT中,图像首先通过一个自动编码器(如变分自编码器VAE)被压缩成较小的潜在表示,然后在这个潜在空间中训练扩散模型。这样做的好处是可以减少直接在高分辨率像素空间训练扩散模型所需的计算量。DiT模型通过Transformer的自注意力机制来处理这些潜在表示,这使得模型能够捕捉到图像的长距离依赖关系,从而生成高质量的图像。
DiT模型通过这种方式,利用Transformer的强大表达能力和扩散模型的生成能力,实现了在图像生成任务中的高效和高质量输出。

(图片来源网络,侵删)

(图片来源网络,侵删)








全部评论
留言在赶来的路上...
发表评论