


(图片来源网络,侵删)

(图片来源网络,侵删)

Freestyler是西北工业大学计算机科学学院音频、语音与语言处理小组(ASLP@NPU)、微软及香港中文大学深圳研究院大数据研究所共同推出的说唱乐生成模型,能直接根据歌词和伴奏创作出说唱音乐。...
FreeScale是南洋理工大学、阿里巴巴集团和复旦大学推出无需微调的推理框架,提升预训练扩散模型生成高分辨率图像和视频的能力。FreeScale基于处理和融合不同尺度的信息,有效解决模型在生成超训练分辨率内容时出现的高频信...
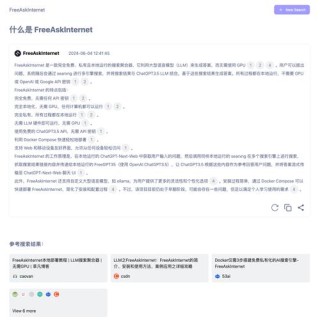
FreeAskInternet是一个免费开源的本地AI搜索引擎,整合了GPT-3.5等先进的大型语言模型(LLM)和SearXNG元搜索引擎,为用户提供搜索和智能答案生成服务。...
Free Video-LLM是创新的无需训练的高效视频语言模型,基于提示引导的视觉感知技术,实现对视频内容的高效理解。模型用预训练的图像LLMs,无需额外训练即可适应视频任务,减少视频帧生成的视觉标记数量,降低计算成本。Fr...
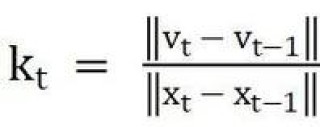
Frames是Runway推出的最新AI图像生成模型,在风格控制和视觉保真度方面取得巨大进步。Frames能维持风格一致性,支持广泛的创意探索,为项目建立特定外观,并生成符合用户美学的变体。基于Frames,用户能精确设计想...


FramePainter 是基于 AI 的交互式图像编辑工具,通过结合视频扩散模型和直观的草图控制,让用户能通过简单的绘制、点击或拖动操作来指示编辑意图,实现对图像的精确修改。...


FramePack 是斯坦福大学开源的AI视频生成模型。基于压缩输入帧的上下文长度,解决视频生成中的“遗忘”和“漂移”问题,让模型能高效处理大量帧,保持较低的计算复杂度。FramePack 仅需 6GB 显存在普通笔记本电脑...
Fractal Generative Models(分形生成模型)是麻省理工学院计算机科学与人工智能实验室和Google DeepMind团队推出的新型图像生成方法。Fractal Generative Models基于分形...


全部评论
留言在赶来的路上...
发表评论