

Free Video-LLM是创新的无需训练的高效视频语言模型,基于提示引导的视觉感知技术,实现对视频内容的高效理解。模型用预训练的图像LLMs,无需额外训练即可适应视频任务,减少视频帧生成的视觉标记数量,降低计算成本。Free Video-LLM在多个视频问答基准上展现出与最先进的视频LLMs相媲美的性能,显著减少了视觉标记的使用,为视频理解任务提供准确性与计算效率之间的理想平衡。

(图片来源网络,侵删)

(图片来源网络,侵删)
Free Video-LLM是创新的无需训练的高效视频语言模型,基于提示引导的视觉感知技术,实现对视频内容的高效理解。模型用预训练的图像LLMs,无需额外训练即可适应视频任务,减少视频帧生成的视觉标记数量,降低计算成本。Free Video-LLM在多个视频问答基准上展现出与最先进的视频LLMs相媲美的性能,显著减少了视觉标记的使用,为视频理解任务提供准确性与计算效率之间的理想平衡。

GaussianAnything 是南洋理工大学 S-Lab 联合上海 AI Lab 等机构推出的 3D 生成框架。GaussianAnything 基于交互式的点云结构化潜空间和级联的流匹配模型,实现高质量、可扩展的 3D...

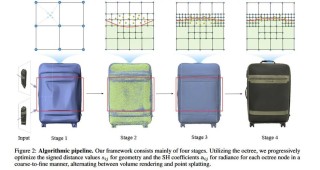
GarDiff是一种创新的虚拟试穿技术,通过使用CLIP和VAE编码来提取服装的外观先验,结合服装聚焦适配器和高频细节增强算法,生成高保真且细节丰富的试穿图像。能精确地对齐服装与人体姿态,保留服装的复杂图案和纹理,提供真实的...

GameNGen是谷歌推出的首个AI游戏引擎,能以每秒20帧的速度实时生成逼真的DOOM游戏画面,甚至让60%的玩家无法区分真假。GameNGen预示着游戏开发可能不再需要传统编程,大幅降低成本,同时为游戏创作带来无限可能。...


GameGen-X是香港科技大学、中国科学技术大学等机构研究人员推出的扩散变换器模型,用在生成和交互控制开放世界游戏视频。模型能模拟游戏引擎功能,如创新角色、动态环境、复杂动作和多样化事件,支持用户用文本指令和键盘控制等多模...


GameGen-O 是腾讯推出的一款基于 Transformer 架构的游戏视频生成模型,专门用于生成开放世界视频游戏。模型能模拟游戏引擎的多种功能,包括生成游戏角色、动态环境、复杂动作等,支持交互控制,支持用户通过文本、操...

GameFactory 是香港大学和快手科技联合提出的创新框架,解决游戏视频生成中的场景泛化难题。框架基于预训练的视频扩散模型,结合开放域视频数据和小规模高质量的游戏数据集,通过多阶段训练策略,实现动作可控的游戏视频生成。...

GTSinger是由浙江大学研究团队推出的大型开源高质量歌声数据集,旨在支持多样化的歌声任务。GTSinger包含80.59小时的专业录音棚录制的歌声,涵盖九种不同语言(汉语、英语、日语、韩语、俄语、西班牙语、法语、德语和意...
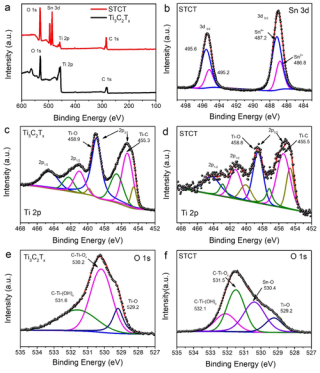
GTA(a benchmark for General Tool Agents)是上海交通大学和上海AI实验室共同推出的基准测试,评估大型语言模型(LLMs)在真实世界场景中调用工具的能力。GTA基于提供真实的用户问题、真实...

全部评论
留言在赶来的路上...
发表评论