

Hallo是由复旦大学、百度公司、苏黎世联邦理工学院和南京大学的研究人员共同提出的一个肖像图像动画技术,可基于语音音频输入来驱动生成逼真且动态的肖像图像视频。该框架采用了基于扩散的生成模型和分层音频驱动视觉合成模块,提高了音频与视觉输出之间的同步精度。Hallo的网络架构整合了UNet去噪器、时间对齐技术和参考网络,以增强动画的质量和真实感,不仅提升了图像和视频的质量,还显著增强了唇动同步的精度,并增加了动作的多样性。

(图片来源网络,侵删)
Hallo是由复旦大学、百度公司、苏黎世联邦理工学院和南京大学的研究人员共同提出的一个肖像图像动画技术,可基于语音音频输入来驱动生成逼真且动态的肖像图像视频。该框架采用了基于扩散的生成模型和分层音频驱动视觉合成模块,提高了音频与视觉输出之间的同步精度。Hallo的网络架构整合了UNet去噪器、时间对齐技术和参考网络,以增强动画的质量和真实感,不仅提升了图像和视频的质量,还显著增强了唇动同步的精度,并增加了动作的多样性。

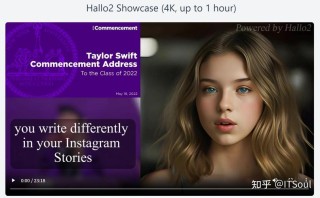
Hallo2是复旦大学、百度公司和南京大学共同推出的音频驱动视频生成模型。能将单张参考图片和持续几分钟的音频输入结合起来,基于可选的文本提示调节肖像表情,生成与音频同步的高分辨率4K视频。...
全部评论
留言在赶来的路上...
发表评论