

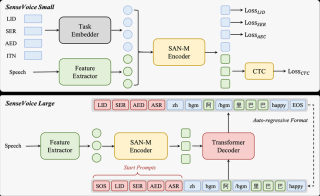
HumanOmni 是专注于人类中心场景的多模态大模型,视觉和听觉模态融合而成。通过处理视频、音频或两者的结合输入,能全面理解人类行为、情感和交互。模型基于超过240万视频片段和1400万条指令进行预训练,采用动态权重调整机制,根据不同场景灵活融合视觉和听觉信息。HumanOmni 在情感识别、面部描述和等方面表现出色,适用于电影分析、特写视频解读和实拍视频理解等多种场景。

(图片来源网络,侵删)

(图片来源网络,侵删)
HumanOmni 是专注于人类中心场景的多模态大模型,视觉和听觉模态融合而成。通过处理视频、音频或两者的结合输入,能全面理解人类行为、情感和交互。模型基于超过240万视频片段和1400万条指令进行预训练,采用动态权重调整机制,根据不同场景灵活融合视觉和听觉信息。HumanOmni 在情感识别、面部描述和等方面表现出色,适用于电影分析、特写视频解读和实拍视频理解等多种场景。

HumanOmniV2 是阿里通义实验室开源的多模态推理模型。模型基于强制上下文总结机制、大模型驱动的多维度奖励体系及基于 GRPO 的优化训练方法,解决多模态推理中全局上下文理解不足和推理路径简单的问题。...

DiffuEraser是基于稳定扩散模型的视频修复模型,以更丰富的细节和更连贯的结构填充视频中的遮罩区域。模型通过结合先验信息来提供初始化和弱条件,有助于减少噪声伪影和抑制幻觉。为了在长序列推理期间提高时间一致性,Diffu...


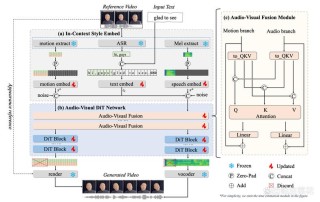
ChatAnyone是阿里巴巴通义实验室推出的实时风格化肖像视频生成框架。通过音频输入,生成具有丰富表情和上半身动作的肖像视频。采用高效分层运动扩散模型和混合控制融合生成模型,能实现高保真度和自然度的视频生成,支持实时交互,...

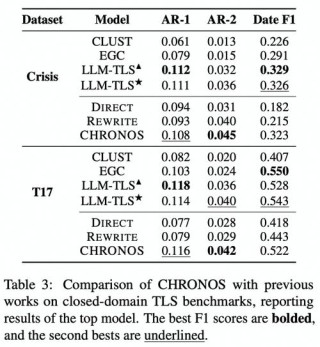
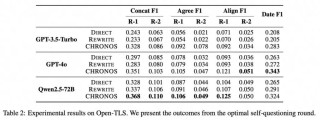
CHRONOS是上海交通大学计算机科学与工程系、阿里巴巴集团通义实验室等机构联合推出的,用在新闻时间线摘要生成的新型框架,基于迭代自问自答的方式,用大型语言模型(LLMs)构建开放域和封闭域的时间线。框架基于生成与新闻主题相...
AnyStory是阿里巴巴通义实验室研发的创新文本到图像生成框架,实现单个和多个主体的高保真个性化图像生成。通过“编码-路由”的方法来建模主体个性化问题。在编码阶段,AnyStory结合强大的ReferenceNet和CLI...

ACE++是阿里巴巴通义实验室推出的先进的图像生成与编辑工具,通过指令化和上下文感知的内容填充技术,实现了高质量的图像创作和编辑功能。...
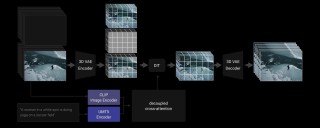

ACE(All-round Creator and Editor)是阿里巴巴集团Tongyi Lab推出的基于扩散变换器的全能图像生成和编辑模型。ACE引入长上下文条件单元(LCU)和统一条件格式,能理解和执行自然语言指令,...

据媒体报道,火爆异常的AI Agent新秀Manus和阿里云旗下大语言模型通义千问达成合作。双方将基于通义千问系列开源模型,在国产模型和算力平台上实现Manus的全部功能;双方将共同推动通用智能体技术的普惠化与商业化落地。...


全部评论
留言在赶来的路上...
发表评论