

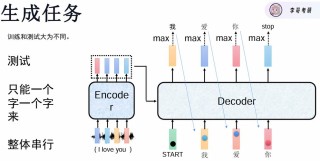
LLaDA(Large Language Diffusion with mAsking)是中国人民大学高瓴AI学院李崇轩、文继荣教授团队和蚂蚁集团共同推出的新型大型语言模型,基于扩散模型框架而非传统的自回归模型(ARM)。LLaDA基于正向掩蔽过程和反向恢复过程建模文本分布,用Transformer作为掩蔽预测器,优化似然下界实现生成任务。LLaDA在预训练阶段使用2.3万亿标记的数据,基于监督微调(SFT)提升指令遵循能力。LLaDA在可扩展性、上下文学习和指令遵循等方面表现出色,在反转推理任务中解决传统ARM的“反转诅咒”问题。其8B参数版本在多项基准测试中与LLaMA3等强模型相当,展现了扩散模型作为自回归模型替代方案的巨大潜力。

(图片来源网络,侵删)










全部评论
留言在赶来的路上...
发表评论