

LLaDA-V是中国人民大学高瓴人工智能学院、蚂蚁集团推出的多模态大语言模型(MLLM),基于纯扩散模型架构,专注于视觉指令微调。模型在LLaDA的基础上,引入视觉编码器和MLP连接器,将视觉特征映射到语言嵌入空间,实现有效的多模态对齐。LLaDA-V在多模态理解方面达到最新水平,超越现有的混合自回归-扩散和纯扩散模型。

(图片来源网络,侵删)

(图片来源网络,侵删)
LLaDA-V是中国人民大学高瓴人工智能学院、蚂蚁集团推出的多模态大语言模型(MLLM),基于纯扩散模型架构,专注于视觉指令微调。模型在LLaDA的基础上,引入视觉编码器和MLP连接器,将视觉特征映射到语言嵌入空间,实现有效的多模态对齐。LLaDA-V在多模态理解方面达到最新水平,超越现有的混合自回归-扩散和纯扩散模型。

MimicMotion是腾讯的研究人员推出的一个高质量的人类动作视频生成框架,利用置信度感知的姿态引导技术,确保视频帧的高质量和时间上的平滑过渡。此外,MimicMotion通过区域损失放大和手部区域增强,显著减少了图像失真...


MimicBrush是由阿里巴巴、香港大学和蚂蚁集团的研究人员推出的AI图像编辑融合框架,允许用户通过简单的操作,在源图像上指定需要编辑的区域,并提供一个包含期望效果的参考图像进行图片编辑。...
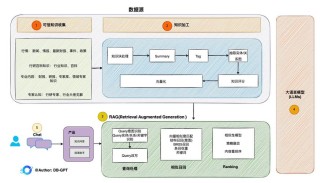

MikuDance是基于扩散模型的动画生成技术,整合混合运动动力学来动画化风格化的角色艺术。MikuDance基于混合运动建模和混合控制扩散技术,解决高动态运动和参考引导错位问题,能显式建模动态相机和角色运动,隐式对齐角色形...


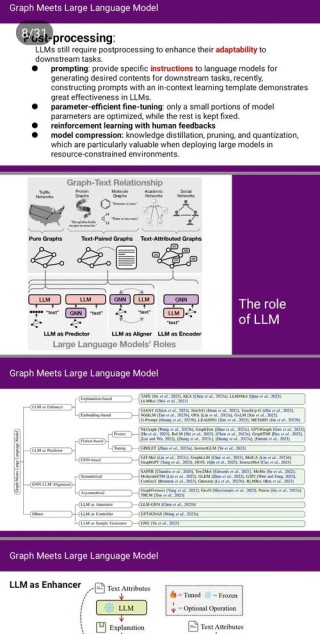
Migician是北京交通大学、华中科技大学和清华大学的研究团队联合推出的多模态大语言模型(MLLM),专门用在自由形式的多图像定位(Multi-Image Grounding, MIG)任务,设计了大规模训练数据集MGro...

Midscene.js是基于AI技术的自动化SDK,通过用大型语言模型(LLM)简化UI自动化测试中的命令。用户用自然语言描述交互步骤或预期数据格式,Midscene.js将执行相应的操作。Midscene.js支持执行动作...
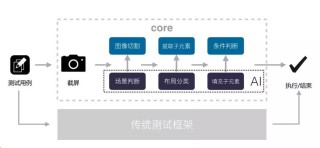

Midjourney V1 是 Midjourney 公司推出的首个AI视频生成模型。支持用户将静态图像转化为动态视频。用户上传图片或在 Midjourney 中生成图片基于“Animate”按钮转变为视频。模型提供自动和手...

Micro LLAMA是精简的教学版LLAMA 3模型实现,能帮助学习者理解大型语言模型架构。整个项目仅约180行代码,便于理解和学习。Micro LLAMA用的是LLAMA 3中最小的8B参数模型,模型本身需15GB存储空...
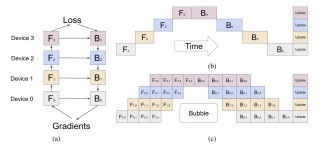
MiLoRA是参数高效的大型语言模型(LLMs)微调方法,通过更新权重分量来矩阵的次要奇异减少计算和内存成本。方法基于奇异值分解(SVD)将权重矩阵分为主要和次要两部分,主要部分包含重要知识,次要部分包含噪声或长尾信息。...


全部评论
留言在赶来的路上...
发表评论