

LLaVA-OneVision是字节跳动推出开源的多模态AI模型,LLaVA-OneVision通过整合数据、模型和视觉表示的见解,能同时处理单图像、多图像和视频场景下的计算机视觉任务。LLaVA-OneVision支持跨模态/场景的迁移学习,特别在图像到视频的任务转移中表现出色,具有强大的视频理解和跨场景能力。

(图片来源网络,侵删)

(图片来源网络,侵删)
LLaVA-OneVision是字节跳动推出开源的多模态AI模型,LLaVA-OneVision通过整合数据、模型和视觉表示的见解,能同时处理单图像、多图像和视频场景下的计算机视觉任务。LLaVA-OneVision支持跨模态/场景的迁移学习,特别在图像到视频的任务转移中表现出色,具有强大的视频理解和跨场景能力。

EX-4D是字节跳动(ByteDance)旗下Pico团队推出的新型4D视频生成框架,能从单目视频输入生成极端视角下的高质量4D视频。框架基于独特的深度防水网格(DW-Mesh)表示,显式建模可见和被遮挡区域,确保在极端相机...

DreamActor-M1是字节跳动推出的先进AI图像动画框架,能将静态人物照片转化为生动的动画视频。采用混合引导机制,结合隐式面部表示、3D头部球体和3D身体骨架等控制信号,实现对人物面部表情和身体动作的精准控制。...

DreamActor-H1是字节跳动推出的基于扩散变换器(Diffusion Transformer, DiT)的框架,支持从配对的人类和产品图像生成高质量的人类产品演示视频。框架注入人类和产品的参考信息,用掩码交叉注意力机...


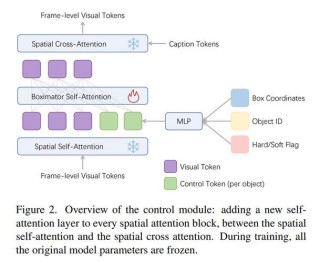
Boximator是有字节跳动的研究团队开发的一种视频合成技术,旨在生成丰富且可控的运动,以增强视频合成的质量和控制性。该技术通过引入两种类型的约束框(硬框和软框)来实现对视频中对象位置、形状或运动路径的精细控制。...
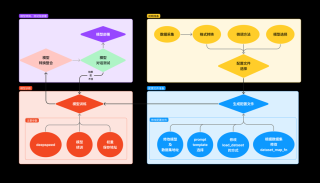
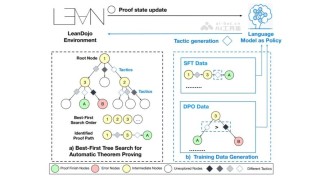
BFS-Prover 是字节跳动豆包大模型团队推出的基于大语言模型(LLM)的自动定理证明系统,通过改进传统的广度优先搜索(BFS)算法,结合专家迭代、直接偏好优化等技术,实现了高效的证明搜索。...
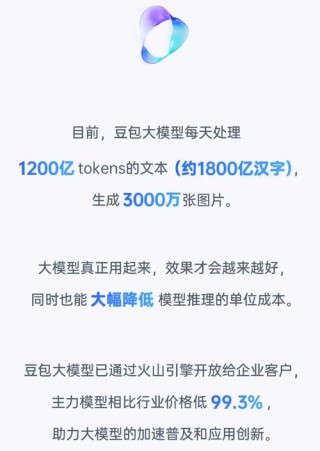
AnimateDiff-Lightning由字节跳动的研究人员最新推出的一个高质量视频生成模型,利用了渐进式对抗性扩散蒸馏技术来实现快速的视频生成。该模型旨在解决现有视频生成模型在速度和计算成本上的主要挑战,同时保持生成视频...
全部评论
留言在赶来的路上...
发表评论