

Mini-LLaVA是一款轻量级的多模态大语言模型,由清华大学和北京航空航天大学的研究团队联合开发。能处理图像、文本和视频输入,实现高效的多模态数据处理。Mini-LLaVA基于Llama 3.1模型,优化了代码结构,在单个GPU上即可运行,适合复杂的视觉-文本关联任务。项目已在GitHub上开源,便于研究者和开发者下载使用。Mini-LLaVA的设计注重代码的可读性和功能的扩展性,支持定制和微调,适应不同的应用场景。

(图片来源网络,侵删)

(图片来源网络,侵删)
Mini-LLaVA是一款轻量级的多模态大语言模型,由清华大学和北京航空航天大学的研究团队联合开发。能处理图像、文本和视频输入,实现高效的多模态数据处理。Mini-LLaVA基于Llama 3.1模型,优化了代码结构,在单个GPU上即可运行,适合复杂的视觉-文本关联任务。项目已在GitHub上开源,便于研究者和开发者下载使用。Mini-LLaVA的设计注重代码的可读性和功能的扩展性,支持定制和微调,适应不同的应用场景。

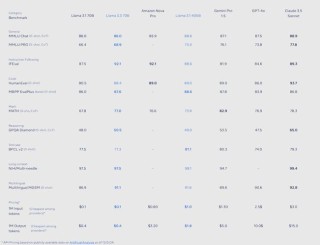
Multi-SWE-bench 是字节跳动豆包大模型团队开源的首个多语言代码修复基准。在SWE-bench基础上,首次覆盖Python之外的7种主流编程语言,包括Java、TypeScript、JavaScript、Go、R...

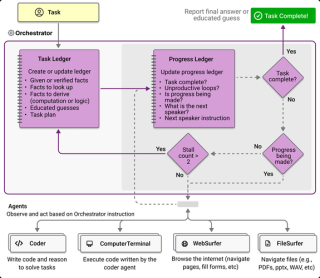
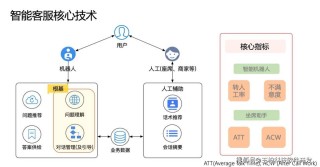
Multi-Agent Orchestrator 是用于管理和协调多个智能代理(Agent)的框架。通过分类器识别用户输入的意图,将请求分配给最适合的代理进行处理,通过对话存储保持上下文连贯性。支持多种类型的代理,如基于大语...
MuCodec是清华大学深圳国际研究生院、腾讯AI实验室和香港中文大学的研究人员共同推出的超低比特率音乐编解码器,能实现音乐的高效压缩与高保真重建。MuCodec基于MuEncoder提取音乐的声学和语义特征,用RVQ技术进...


Mu是微软推出的小参数语言模型,仅3.3亿参数,支持在 NPU 和边缘设备上高效运行。模型基于编码器解码器架构,基于硬件感知优化、模型量化及特定任务微调,实现每秒超100 tokens的响应速度。...


MoviiGen 1.1 是ZulutionAI推出的专注于生成电影级画质视频的AI模型。模型基于 Wan2.1 微调而成,经过专业电影制作人和AIGC创作者在60个美学维度上的评估,表现出色。...

MovieDreamer是浙江大学联合阿里巴巴专为长视频研发的AI视频生成框架。结合自回归模型和扩散渲染技术,能生成具有复杂情节和高视觉质量的长视频。...

Movie Gen 是 Meta 推出的AI视频生成工具,能根据文本提示生成和编辑视频,为视频配上同步音频。技术包括创建长达16秒的高清视频、为现有视频配上音频、编辑视频以及基于照片制作定制视频。...

MotionGen是元象科技推出的3D动作生成模型,结合了大模型、物理仿真和强化学习算法,支持用户仅通过简单文本指令即可快速生成逼真且流畅的3D动作。MotionGen极大地简化了3D动画的制作过程,提高了创作效率。Moti...


全部评论
留言在赶来的路上...
发表评论