

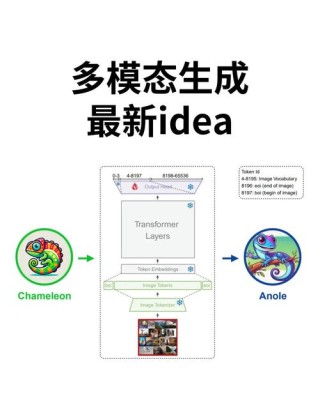
RLCM(Reinforcement Learning for Consistency Model)是康奈尔大学推出用在优化文本到图像生成模型的框架,基于强化学习方法微调一致性模型适应特定任务的奖励函数。将一致性模型的多步推理过程建模为马尔可夫决策过程(MDP),基于策略梯度算法优化模型参数,用最大化与任务相关的奖励。与传统的扩散模型相比,RLCM在训练和推理速度上显著更快,能生成高质量的图像。RLCM能适应难以用提示表达的目标,如图像可压缩性和美学质量等,展示了在任务特定奖励优化和快速生成方面的优势。

(图片来源网络,侵删)

(图片来源网络,侵删)







全部评论
留言在赶来的路上...
发表评论