

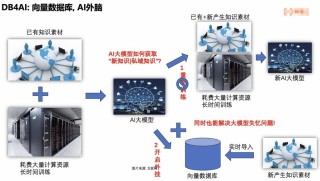
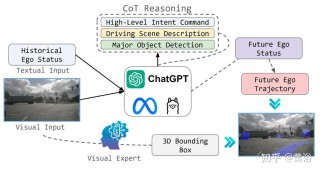
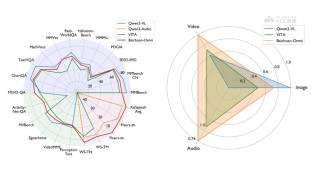
SlowFast-LLaVA-1.5(简称SF-LLaVA-1.5)是专为长视频理解设计的高效视频大语言模型。基于双流(SlowFast)机制,平衡处理更多输入帧与减少每帧令牌数量之间的关系,能捕捉详细的空间特征,且能高效地处理长时序运动信息。模型包含从1B到7B参数规模的模型,基于简化的两阶段训练流程和高质量的公开数据集混合训练而成,模型在长视频理解任务中表现出色,能在图像理解任务中保持较强的性能,在小规模模型上展现出显著优势,为轻量化和移动友好型视频理解应用提供有力支持。

(图片来源网络,侵删)

(图片来源网络,侵删)






全部评论
留言在赶来的路上...
发表评论