

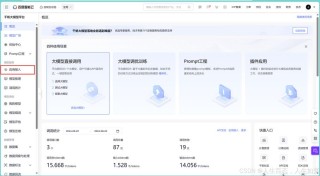
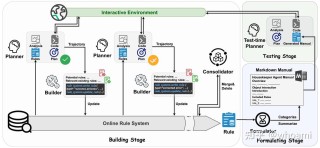
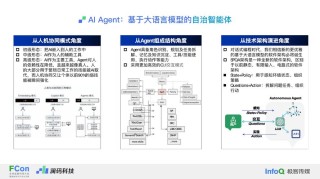
SWE-Lancer 是 OpenAI 推出的大模型基准测试,评估前沿语言模型(LLMs)在自由职业软件工程任务中的表现。包含来自 Upwork 的 1400 多个任务,总价值达 100 万美元,分为个人贡献者(IC)任务和管理任务。IC 任务涵盖从简单修复到复杂功能开发,管理任务则要求模型选择最佳技术方案。SWE-Lancer 的任务设计贴近真实软件工程场景,涉及全栈开发、API 交互等复杂场景。通过专业工程师的验证和测试,基准测试能评估模型的编程能力,衡量在实际任务中的经济效益。

(图片来源网络,侵删)

(图片来源网络,侵删)










全部评论
留言在赶来的路上...
发表评论