

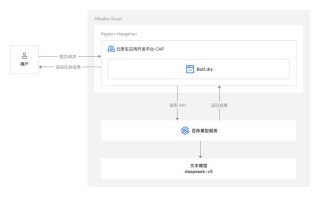
Tarsier2是字节跳动推出的先进的大规模视觉语言模型(LVLM),生成详细且准确的视频描述,在多种视频理解任务中表现出色。模型通过三个关键升级实现性能提升,将预训练数据从1100万扩展到4000万视频文本对,丰富了数据量和多样性;在监督微调阶段执行精细的时间对齐;基于模型采样自动构建偏好数据,应用直接偏好优化(DPO)训练。 在DREAM-1K基准测试中,Tarsier2-7B的F1分数比GPT-4o高出2.8%,比Gemini-1.5-Pro高出5.8%。在15个公共基准测试中取得了新的最佳结果,涵盖视频问答、视频定位、幻觉测试和具身问答等任务。

(图片来源网络,侵删)

(图片来源网络,侵删)












全部评论
留言在赶来的路上...
发表评论