

SafeEar是由浙江大学和清华大学联合开发的AI音频伪造检测框架,保护用户隐私的同时检测音频伪造。采用基于神经音频编解码器的解耦模型,分离语音的声学信息和语义信息,用声学信息进行检测,有效防止隐私泄露。SafeEar在多个基准数据集上表现优异,等错误率(EER)低至2.02%,能抵御内容恢复攻击。SafeEar提供了多语言支持,构建了包含150万条多语种音频数据的CVoiceFake数据集,为语音伪造检测研究提供了宝贵的资源。

(图片来源网络,侵删)

(图片来源网络,侵删)
SafeEar是由浙江大学和清华大学联合开发的AI音频伪造检测框架,保护用户隐私的同时检测音频伪造。采用基于神经音频编解码器的解耦模型,分离语音的声学信息和语义信息,用声学信息进行检测,有效防止隐私泄露。SafeEar在多个基准数据集上表现优异,等错误率(EER)低至2.02%,能抵御内容恢复攻击。SafeEar提供了多语言支持,构建了包含150万条多语种音频数据的CVoiceFake数据集,为语音伪造检测研究提供了宝贵的资源。

TesserAct 是创新的 4D 具身世界模型,能预测 3D 场景随时间的动态演变,响应具身代理的动作。通过训练 RGB-DN(RGB、深度和法线)视频数据来学习,超越了传统的 2D 模型,能将详细的形状、配置和时间变化纳...


TeleChat2-115B是由中国电信人工智能研究院(TeleAI)研发的大型语言模型,属于星辰语义大模型系列。基于国产算力进行训练,采用10万亿Tokens的中英文高质量语料。与前代模型相比,TeleChat2-115B...


TeleAI-t1-preview是中国电信人工智能研究院发布的“复杂推理大模型”,具备强大的逻辑推理与数学推导能力。通过强化学习训练方法,引入探索、反思等思考范式,提升了复杂问题的解答精度。...

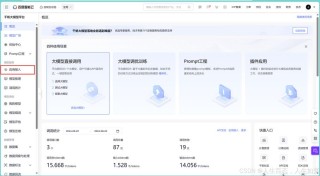
TeleAI 视频生成大模型是中国电信AI研究院推出的视频生成模型,基于两阶段生成框架:先根据文本描述创建分镜头草图,再基于草图生成视频。TeleAI 视频生成大模型能确保视频中主体外观的一致性,精确控制动作和外观,实现复杂...


Teacher2Task是谷歌团队推出的多教师学习框架,引入教师特定的输入标记和重新构思训练过程,消除对手动聚合启发式方法的需求。框架不依赖聚合标签,将训练数据转化为N+1个任务,包括N个辅助任务预测每位教师的标记风格,及一...
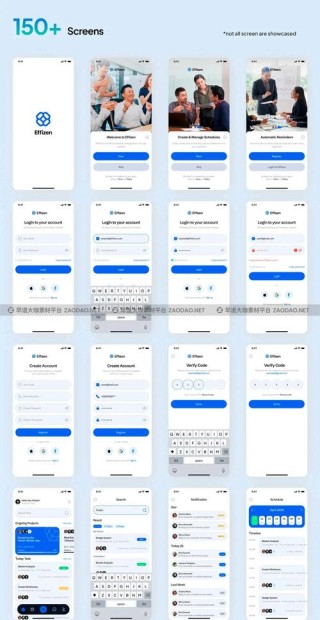

TaskWeaver是由微软推出的一个代码优先的AI智能体框架,专注于无缝规划和执行数据分析任务。基于代码片段解释用户请求,高效协调各种插件(以函数形式)执行数据分析任务,支持状态化的执行方式。TaskWeaver支持丰富的...
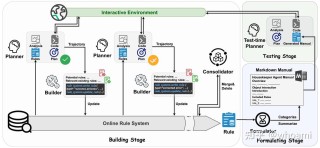
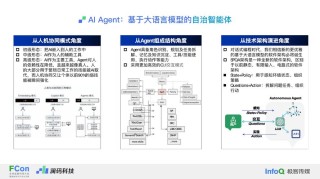
Tarsier2是字节跳动推出的先进的大规模视觉语言模型(LVLM),生成详细且准确的视频描述,在多种视频理解任务中表现出色。模型通过三个关键升级实现性能提升,将预训练数据从1100万扩展到4000万视频文本对,丰富了数据量...

TaoAvatar是阿里巴巴集团研究团队推出的高保真、轻量级的3D全身对话虚拟人技术。基于3D高斯溅射技术,能生成照片级逼真的3D全身虚拟形象,支持高分辨率渲染且存储需求低。...


全部评论
留言在赶来的路上...
发表评论