

SmolVLA 是 开源的轻量级视觉-语言-行动(VLA)模型,专为经济高效的机器人设计。拥有4.5亿参数,模型小巧,可在CPU上运行,单个消费级GPU即可训练,能在MacBook上部署。SmolVLA 完全基于开源数据集训练,数据集标签为“lerobot”。

(图片来源网络,侵删)

(图片来源网络,侵删)
SmolVLA 是 开源的轻量级视觉-语言-行动(VLA)模型,专为经济高效的机器人设计。拥有4.5亿参数,模型小巧,可在CPU上运行,单个消费级GPU即可训练,能在MacBook上部署。SmolVLA 完全基于开源数据集训练,数据集标签为“lerobot”。

VideoLLaMB 是一种创新的长视频理解框架,通过引入记忆桥接层和递归记忆令牌来处理视频数据,确保在分析时不丢失关键视觉信息。模型特别设计用于理解长时间视频内容,保持语义连续性,并在多种任务中表现出色,如视频问答、自我中...
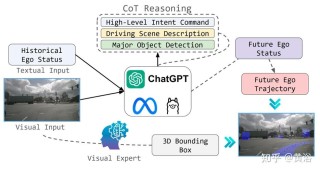
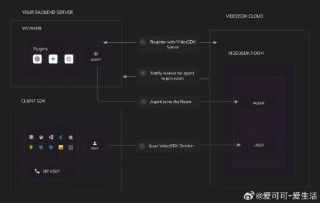
VideoLLaMA3 是阿里巴巴开源的前沿多模态基础模型,专注于图像和视频理解。基于 Qwen 2.5 架构,结合了先进的视觉编码器(如 SigLip)和强大的语言生成能力,能高效处理长视频序列,支持多语言的视频内容分析和...
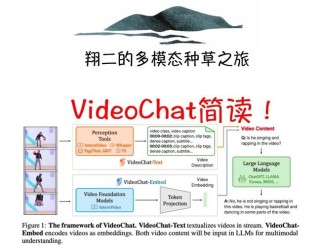
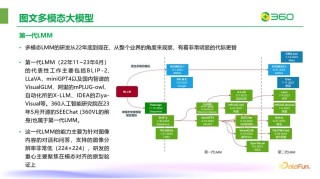
VideoJAM是Meta推出的,用在增强视频生成模型运动连贯性的框架。基于引入联合外观-运动表示,让模型在训练阶段同时学习预测视频的像素和运动信息,在推理阶段基于模型自身的运动预测作为动态引导信号,生成更连贯的运动。...
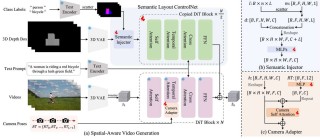
VideoGrain 是悉尼科技大学和浙江大学推出的零样本多粒度视频编辑框架,能实现类别级、实例级和部件级的精细视频修改。VideoGrain基于调节时空交叉注意力和自注意力机制,增强文本提示对目标区域的控制能力,且保持区域...
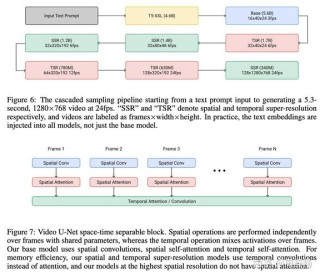
VideoGigaGAN是由Adobe和马里兰大学的研究人员提出的一种新型的生成式视频超分辨率(VSR)模型,最高可将视频分辨率提升8倍,将模糊的视频放大为具有丰富细节和时间连贯性的高清视频。...
VideoGameBunny(VGB)是一个专为视频游戏设计的开源大型多模态模型,由加拿大阿尔伯塔大学研究团队开发。它能理解和生成多种语言的游戏相关内容,支持高度定制化,具备强大的文本生成能力。...


VideoFusion 是开源的短视频拼接与处理软件,专为高效视频编辑设计。支持自动去除视频中的黑边、水印和字幕,能将视频自动旋转为横屏或竖屏,适配不同播放场景。软件具备降噪、去抖动、音量平衡等功能,能提升视频画质。...


VideoDoodles是Adobe公司联合多所大学推出的AI视频编辑框架。支持用户在视频中轻松插入手绘动画,实现与视频内容的无缝融合。通过预处理视频帧,系统提供平面画布,用户可以视频上绘制动画,系统自动处理透视和遮挡效果。...
全部评论
留言在赶来的路上...
发表评论