

SmolVLM是Hugging Face推出的轻量级视觉语言模型,专为设备端推理设计。以20亿参数量,实现了高效内存占用和快速处理速度。SmolVLM提供了三个版本以满足不同需求:SmolVLM-Base:适用于下游任务的微调。SmolVLM-Synthetic:基于合成数据进行微调。SmolVLM-Instruct:指令微调版本,可直接应用于交互式应用中。模型借鉴Idefics3理念,采用SmolLM2 1.7B作为语言主干,通过像素混洗技术提升视觉信息压缩效率。在Cauldron和Docmatix数据集上训练,优化了图像编码和文本处理能力。

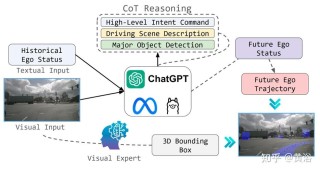
(图片来源网络,侵删)

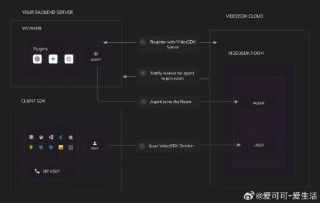
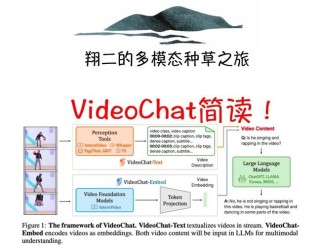
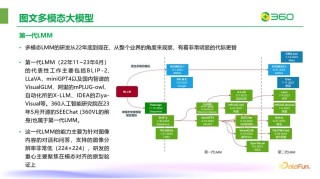
(图片来源网络,侵删)





全部评论
留言在赶来的路上...
发表评论