

MAGREF(Masked Guidance for Any‑Reference Video Generation)是字节跳动推出的多主体框架。MAGREF仅需一张参考图像和文本提示,能生成高质量、主体一致的视频,支持单人、多人及人物与物体、背景的复杂交互场景。基于区域感知动态掩码和像素级通道拼接机制,MAGREF能精准复刻身份特征,保持视频中人物、物体和背景的协调性与一致性,适用内容创作、广告制作等多种场景,展现极强的生成能力和可控性。

(图片来源网络,侵删)

(图片来源网络,侵删)
MAGREF(Masked Guidance for Any‑Reference Video Generation)是字节跳动推出的多主体框架。MAGREF仅需一张参考图像和文本提示,能生成高质量、主体一致的视频,支持单人、多人及人物与物体、背景的复杂交互场景。基于区域感知动态掩码和像素级通道拼接机制,MAGREF能精准复刻身份特征,保持视频中人物、物体和背景的协调性与一致性,适用内容创作、广告制作等多种场景,展现极强的生成能力和可控性。

Loopy是字节跳动推出的音频驱动的AI视频生成模型,用户可以让一张静态照片动起来,照片中的人物根据给定的音频文件进行面部表情和头部动作的同步,生成逼真的动态视频。Loopy基于先进的扩散模型技术,无需额外的空间信号或条件,...

ImmerseGen是字节跳动的PICO团队和浙江大学联合推出的创新3D世界生成框架。框架根据用户输入的文字提示,基于Agent引导的资产设计和排列,生成带有alpha纹理的紧凑Agent,创建全景3D世界。...

HeadGAP是字节跳动和上海科技大学共同推出的3D头像生成模型,仅用少量图片快速生成逼真的3D头像。采用先验学习和个性化创建阶段的框架,基于大规模多视角动态数据集导出的3D头部先验信息。通过高斯Splatting自动解码网...


FlowGram是字节跳动开源的基于节点编辑的可视化工作流搭建引擎,帮助开发者快速构建固定布局或自由连线布局的工作流。支持两种布局模式:固定布局适合顺序工作流和决策树,提供层次化结构和灵活的分支、复合节点;自由布局支持节点自...

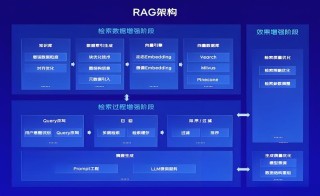
Eino 是字节跳动开源的大模型应用开发框架,能帮助开发者高效构建基于大模型的 AI 应用。Eino以 Go 语言为基础,具备稳定的内核、灵活的扩展性和完善的工具生态。Eino 的核心是组件化设计,基于定义不同的组件(如 C...
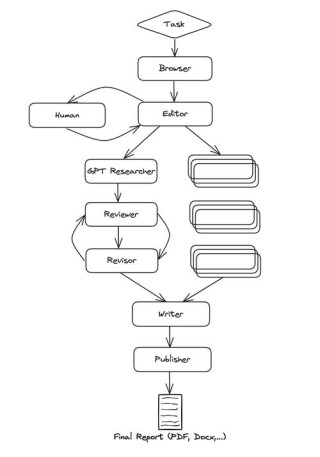
DeerFlow 是字节跳动开源的深度研究框架,能帮助用户高效完成复杂的研究任务。DeerFlow结合语言模型与多种工具,如网络搜索、爬虫和 Python 执行,能快速生成全面的研究报告、播客和演示文稿。...
全部评论
留言在赶来的路上...
发表评论