

VRAG-RL是阿里巴巴通义大模型团队推出的视觉感知驱动的多模态RAG推理框架,专注于提升视觉语言模型(VLMs)在处理视觉丰富信息时的检索、推理和理解能力。基于定义视觉感知动作空间,让模型能从粗粒度到细粒度逐步获取信息,更有效地激活模型的推理能力。VRAG-RL引入综合奖励机制,结合检索效率和基于模型的结果奖励,优化模型的检索和生成能力。在多个基准测试中,VRAG-RL显著优于现有方法,展现在视觉丰富信息理解领域的强大潜力。

(图片来源网络,侵删)

(图片来源网络,侵删)
VRAG-RL是阿里巴巴通义大模型团队推出的视觉感知驱动的多模态RAG推理框架,专注于提升视觉语言模型(VLMs)在处理视觉丰富信息时的检索、推理和理解能力。基于定义视觉感知动作空间,让模型能从粗粒度到细粒度逐步获取信息,更有效地激活模型的推理能力。VRAG-RL引入综合奖励机制,结合检索效率和基于模型的结果奖励,优化模型的检索和生成能力。在多个基准测试中,VRAG-RL显著优于现有方法,展现在视觉丰富信息理解领域的强大潜力。

Wan2.2-S2V 是开源的多模态视频生成模型,仅需一张静态图片和一段音频,能生成电影级数字人视频,视频时长可达分钟级,且支持多种图片类型和画幅。...
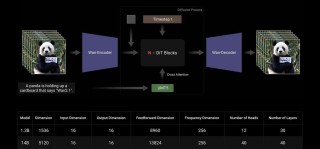

Self-Lengthen是阿里巴巴千问团队推出的创新的迭代训练框架,能提升大型语言模型(LLMs)生成长文本的能力。框架基于两个角色,生成器和扩展器协同工作,生成器负责生成初始响应,扩展器将响应拆分、扩展产生更长的文本。...


Qwen2.5-Turbo是阿里推出的先进语言模型,将上下文长度从 128k 扩展到了 1M ,相当于100万个英文单词或150万个汉字。扩展让模型能处理更长的文本,如长篇小说、演讲稿或代码。Qwen2.5-Turbo用高效...

Qwen2-Audio是阿里通义千问团队最新推出的开源AI语音模型,支持直接语音输入和多语言文本输出。具备语音聊天、音频分析功能,支持超过8种语言。Qwen2-Audio在多个基准数据集上表现优异,现已集成至Hugging...


Qwen-TTS是阿里通义推出的语音合成模型,具备自然、稳定、快速的特点。模型能根据文本和音色参数输出高质量音频,支持中英文及方言合成,如北京话、上海话、四川话等。模型基于大规模语料训练,生成效果接近人类水平。...
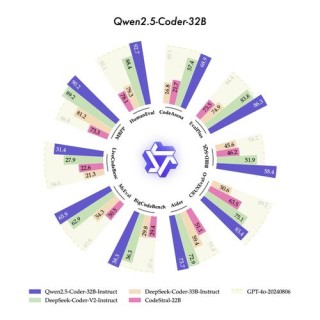
Qwen-MT 是阿里通义千问团队推出的机器翻译模型,基于强大的 Qwen3 架构开发。模型支持 92 种语言的高质量互译,覆盖全球 95% 以上的人口,能满足多样化的跨语言交流需求。模型基于轻量级 MoE 架构,具备低延迟...


Qwen-Flash是阿里通义千问推出的Qwen3系列Flash模型,版本号为qwen-flash-2025-07-28。模型在通用能力、推理能力、中英文知识处理及Agent能力上均有显著提升,特别优化主观开放类任务的处理,...

Qwen-Agent是基于通义千问模型(Qwen)的开源Agent开发框架,支持开发者用Qwen模型的指令遵循、工具使用、规划和记忆能力构建智能代理应用。Qwen-Agent支持函数调用、代码解释器和RAG(检索增强生成)等...
全部评论
留言在赶来的路上...
发表评论