

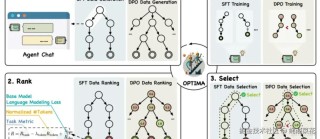
WebRL是清华大学、智谱AI联合推出的自我进化的在线课程强化学习框架,训练使用开放大型语言模型(LLMs)的高性能网络代理。WebRL动态生成任务、结果监督奖励模型(ORM)评估任务成功与否,及自适应强化学习策略,解决训练任务稀缺、反馈信号稀疏和在线学习中的策略分布漂移等挑战。WebRL显著提升了Llama-3.1和GLM-4等模型在WebArena-Lite基准测试中的成功率,超越专有LLM API和之前训练的网络代理,证明在提升开源LLMs网络任务能力方面的有效性。

(图片来源网络,侵删)

(图片来源网络,侵删)










全部评论
留言在赶来的路上...
发表评论