

AnimateDiff是由上海人工智能实验室、香港中文大学和斯坦福大学的研究人员推出的一款将个性化的文本到图像模型扩展为动画生成器的框架,其核心在于它能够利用从大规模视频数据集中学习到的运动先验知识,可以作为 Stable Diffusion 文生图模型的插件,允许用户将静态图像转换为动态动画。该框架的目的是简化动画生成的过程,使得用户能够通过文本描述来控制动画的内容和风格,而无需进行特定的模型调优。

(图片来源网络,侵删)

(图片来源网络,侵删)
AnimateDiff是由上海人工智能实验室、香港中文大学和斯坦福大学的研究人员推出的一款将个性化的文本到图像模型扩展为动画生成器的框架,其核心在于它能够利用从大规模视频数据集中学习到的运动先验知识,可以作为 Stable Diffusion 文生图模型的插件,允许用户将静态图像转换为动态动画。该框架的目的是简化动画生成的过程,使得用户能够通过文本描述来控制动画的内容和风格,而无需进行特定的模型调优。

ChatUI 是阿里团队推出的开源智能对话式 UI 组件库,能帮助开发者快速构建高质量的聊天应用,提供响应式设计、国际化、主题定制等功能。ChatUI 基于阿里巴巴 Alime Chatbot 的最佳实践,用 TypeScr...
ChatTTSPlus是ChatTTS的扩展版本,基于集成TensorRT加速、语音克隆和移动模型部署等先进技术,提升语音合成的性能和灵活性。在Windows平台上,能实现超过3倍的加速,从28 tokens/s提升到110...

ChatTTS是一款专为对话场景设计的支持中英文的文本转语音(TTS)模型,基于约10万小时的中英文数据进行训练,能够生成高质量、自然流畅的对话语音。...

ChatTS-14B 是字节跳动研究团队开源的专注于时间序列理解和推理的大型语言模型,参数量达 140 亿。基于 Qwen2.5-14B-Instruct 微调而成,通过合成数据对齐技术显著提升了在时间序列任务中的表现。...


ChatMusician是由Multimodal Art Projection Research Community、Skywork AI和香港科技大学的研究人员推出的,一个开源的用于理解和生成音乐的大型语言模型。能够在不依...
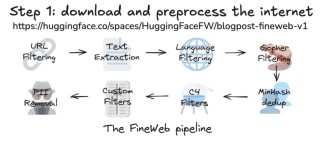

ChatMLX是一个基于大型语言模型(LLM)的高性能MacOS聊天应用,基于MLX框架实现与数据的交互。应用通过自然语言处理技术,让用户与数据进行对话,支持文本文档、PDF文件和YouTube视频。ChatMLX支持多种语...
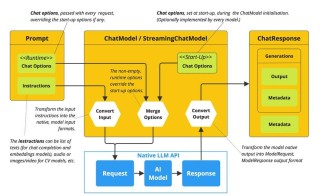
ChatMCP 是基于模型上下文协议(MCP)的 AI 聊天客户端,支持与各种大型语言模型(LLM)如 OpenAI、Claude 和 OLLama 等进行交互。ChatMCP具备自动化安装 MCP 服务器、SSE 传输支持...

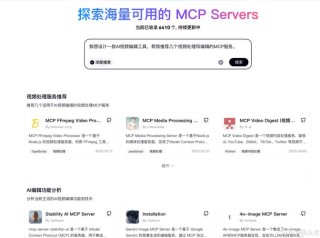
ChatLearn 是由阿里云推出的一个灵活、易用、高效的大规模Alignmant 训练框架。ChatLearn是为了支持大型语言模型(LLMs)的 Alignment 训练而设计的。ChatLearn 提供了 RLHF、D...
全部评论
留言在赶来的路上...
发表评论