

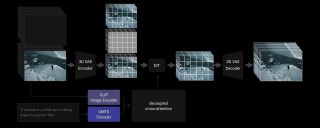
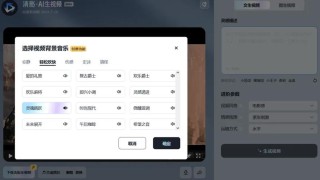
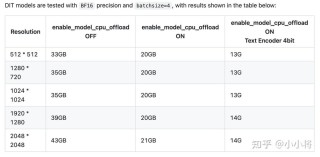
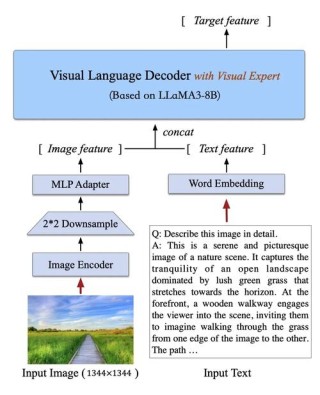
CogVideoX-2是智谱 AI 推出的文本到模型,基于先进的 3D 变分自编码器(VAE),将视频数据压缩到原本的 2%,减少资源使用,同时确保视频帧之间的连贯流畅。 通过独特的 3D 旋转位置编码技术,视频在时间轴上能够自然流动,赋予画面生命力。模型结构、训练方法、数据工程全面更新,图生视频基础模型能力大幅度提升38%。生成更可控,支持画面主体进行大幅度运动,同时保持画面稳定性。指令遵从能力行业领先,能够理解和实现各种复杂prompt。能驾驭各种艺术风格,画面美感大幅提升支持 FP16、BF16、FP32、FP8 和 INT8 等多种推理精度。

(图片来源网络,侵删)

(图片来源网络,侵删)








全部评论
留言在赶来的路上...
发表评论