


(图片来源网络,侵删)

(图片来源网络,侵删)

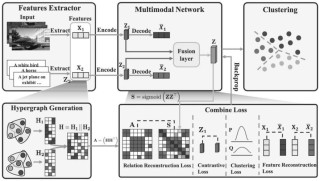
ENEL(Exploring the Potential of Encoder-free Architectures in 3D LMMs)是创新的无编码器3D大型多模态模型(3D LMM),解决传统编码器架构在3D理解任务...
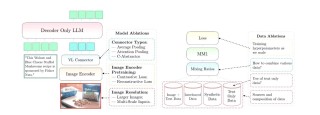
EMOVA(EMotionally Omni-present Voice Assistant)是多模态全能模型,是香港科技大学、香港大学和华为诺亚方舟实验室等机构共同推出的。EMOVA能处理图像、文本和语音模态,实现能看、能...
EMO2 (End-Effector Guided Audio-Driven Avatar Video Generation)是阿里巴巴智能计算研究院开发的音频驱动头像视频生成技术,全称为“末端效应器引导的音频驱动头像视频生...


EMO(Emote Portrait Alive)是一个由阿里巴巴集团智能计算研究院的研究人员开发的框架,一个音频驱动的AI肖像视频生成系统,能够通过输入单一的参考图像和语音音频,生成具有表现力的面部表情和各种头部姿势的视频...

EMMA-X是新加坡科技设计大学推出的具有70亿参数的具身多模态动作模型,在有根据的链式思维(CoT)推理数据上微调OpenVLA创建。EMMA-X结合层次化的具身数据集,包含3D空间运动、2D夹爪位置和有根据的推理,及推出...
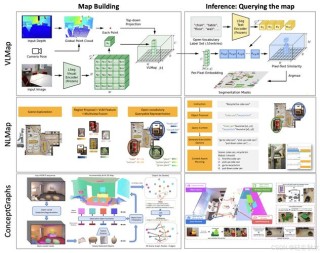
EMMA是Waymo基于Gemini模型推出的端到端自动驾驶多模态模型,能将原始相机传感器数据直接映射到驾驶特定输出,如规划轨迹、感知对象和道路图元素。EMMA将非传感器输入和输出表示为自然语言文本,用预训练大型语言模型的世...


EMAGE(Expressive Masked Audio-conditioned GEsture modeling)是清华大学、东京大学、庆应义塾大学等机构推出的用在生成全身共语手势框架。EMAGE能根据音频和部分遮蔽的手...
ELLA(Efficient Large Language Model Adapter,高效的大模型适配器)是由腾讯的研究人员推出的一种新型方法,旨在提升文本到图像生成模型在处理复杂文本提示时的语义对齐能力。...

全部评论
留言在赶来的路上...
发表评论