

INFP是音频驱动的头部生成框架,专为双人对话交互设计。能自动在对话音频引导下进行角色的转换,无需手动分配角色和角色切换。INFP包括两个阶段:基于动作头部模仿阶段和音频引导动作生成阶段,通过实验和可视化展示,验证了INFP方法的卓越性能和有效性。INFP提出了大规模双人对话数据集DyConv,以支持该研究领域的进步。

(图片来源网络,侵删)

(图片来源网络,侵删)
INFP是音频驱动的头部生成框架,专为双人对话交互设计。能自动在对话音频引导下进行角色的转换,无需手动分配角色和角色切换。INFP包括两个阶段:基于动作头部模仿阶段和音频引导动作生成阶段,通过实验和可视化展示,验证了INFP方法的卓越性能和有效性。INFP提出了大规模双人对话数据集DyConv,以支持该研究领域的进步。

LVCD(Large Video Color Diffusion)是一个专为动画视频线稿上色设计的视频扩散框架,能将黑白线稿自动转化为彩色动画视频。LVCD使用了一种先进的扩散模型,可以同时处理整个视频序列,保证每一帧的颜色...


LTXV-13B 是Lightricks推出的开源 AI 视频生成模型,拥有 130 亿参数。具备极高的生成速度,比同类产品快 30 倍,能在普通消费级显卡(如 4090/5090)上运行,推理速度快且成本低。...


LTX Video是Lightricks推出的开源AI视频生成模型,能在4秒内生成5秒的高质量视频,速度超过观看速度。基于2亿参数的DiT架构,确保帧间平滑运动和结构一致性,解决了早期视频生成模型的关键限制。LTX Vide...
LTM-2-mini是Magic公司推出的支持1亿token上下文AI模型,能处理相当于1000万行代码或750本小说的内容。LTM-2-mini采用序列维度算法,计算效率比Llama 3.1 405B的注意力机制高出约10...
LOKI是由中山大学和上海AI Lab联合提出的合成数据检测基准,旨在全面评估大型多模态模型(LMMs)在识别视频、图像、3D、文本和音频等多种模态合成数据的能力。包含18,000多个问题,覆盖26个子类别,采用多层次标注,...

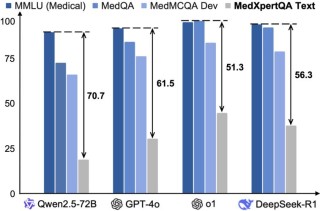
LMMs-Eval 是一个专为多模态AI模型设计的统一评估框架,提供标准化、广泛覆盖且成本效益高的模型性能评估解决方案。包含超过50个任务和10多个模型,通过透明和可复现的评估流程,帮助研究者和开发者全面理解模型能力。...
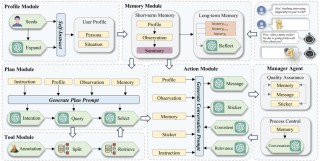
LMEval 是谷歌推出的开源框架,用在简化大型模型(LLMs)的跨提供商评估。框架支持多模态(文本、图像、代码)和多指标评估,兼容 Google、OpenAI、Anthropic 等主流模型提供商。LMEval 基于增量评...
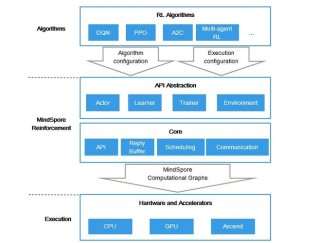
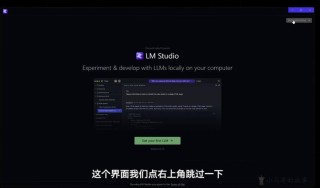
LM Studio 是一个本地大语言模型 (LLM 应用平台,开源、傻瓜、一站式部署本地大模型。包括但不限于Llama、MPT、Gemma等,LM Studio 提供了一个图形用户界面(GUI),即使是非技术人员也能轻松地...
全部评论
留言在赶来的路上...
发表评论