

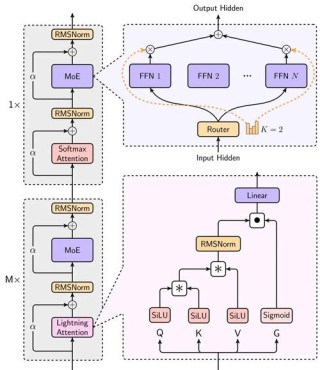
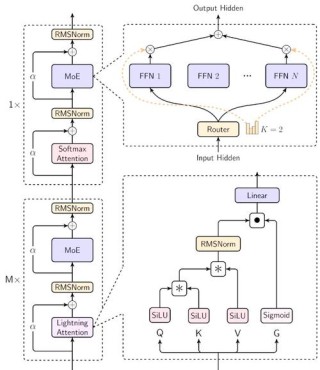
KTransformers是清华大学KVCache.AI团队联合趋境科技推出的开源项目,能优化大语言模型的推理性能,降低硬件门槛。KTransformers基于GPU/CPU异构计算策略,用MoE架构的稀疏性,支持在仅24GB显存的单张显卡上运行DeepSeek-R1、V3的671B满血版,预处理速度最高达到286 tokens/s,推理生成速度最高能达到14 tokens/s。项目用基于计算强度的offload策略、高性能算子和CUDA Graph优化等技术,显著提升推理速度。

(图片来源网络,侵删)

(图片来源网络,侵删)






全部评论
留言在赶来的路上...
发表评论