

LLM2LLM是创新的迭代数据增强策略,提升大型语言模型(LLM)在数据稀缺情况下的性能。方法通过基于一个强大的教师模型来生成合成数据,增强学生模型的训练数据集。具体来说,学生模型首先在有限的种子数据上进行微调,然后教师模型会识别学生模型在预测中的错误,并基于这些错误生成新的合成数据。这些合成数据随后被加入到训练集中,形成一个循环迭代的过程。LLM2LLM的优势在于能够有效地减少对大规模标注数据的依赖,同时针对性地解决学生模型的弱点,在低数据量任务中显著提高模型的准确性和鲁棒性。这种方法特别适用于数据获取成本高昂的领域,如医疗诊断和专业领域研究。

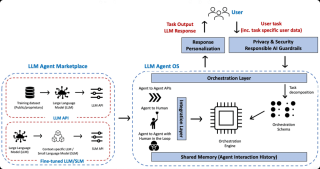
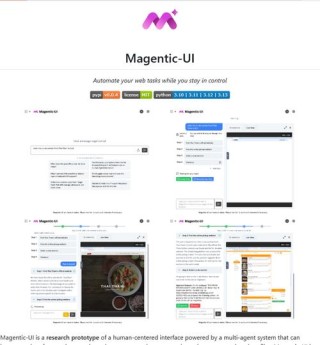
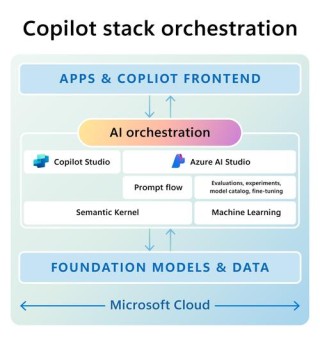
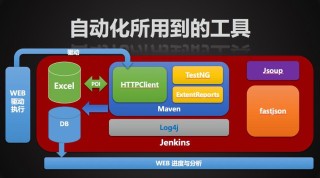
(图片来源网络,侵删)




全部评论
留言在赶来的路上...
发表评论