

LaTRO(Latent Reasoning Optimization)是先进的框架,提升大型语言模型(LLMs)在复杂推理任务中的表现。基于将推理过程类比为从潜在分布中采样,用变分推断方法进行优化,LaTRO让模型自我改进,增强生成和评估推理路径的能力。这一方法无需依赖外部反馈或奖励机制,有效解锁并进一步激发预训练语言模型内在的推理潜能,推动构建更智能、更自主的问题解决系统。

(图片来源网络,侵删)

(图片来源网络,侵删)
LaTRO(Latent Reasoning Optimization)是先进的框架,提升大型语言模型(LLMs)在复杂推理任务中的表现。基于将推理过程类比为从潜在分布中采样,用变分推断方法进行优化,LaTRO让模型自我改进,增强生成和评估推理路径的能力。这一方法无需依赖外部反馈或奖励机制,有效解锁并进一步激发预训练语言模型内在的推理潜能,推动构建更智能、更自主的问题解决系统。

MAI-DS-R1 是微软基于 DeepSeek R1 改进的AI模型。MAI-DS-R1基于后训练优化,支持响应 99.3% 的敏感话题提示,比原版提升 2 倍,将有害内容风险降低 50%。MAI-DS-R1 在推理能力上...

MAGREF(Masked Guidance for Any‑Reference Video Generation)是字节跳动推出的多主体视频生成框架。MAGREF仅需一张参考图像和文本提示,能生成高质量、主体一致的视频,支...

MAGI-1 是 Sand AI 开源的全球首个自回归视频生成大模型,采用自回归架构,通过逐块预测视频序列生成流畅自然的视频,支持无限扩展和一镜到底的长视频生成。...

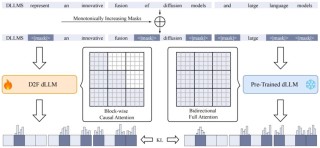
MAETok(Masked Autoencoders Tokenizer)是卡内基梅隆大学、香港大学、北京大学等机构推出的用在扩散模型的新型图像标记化方法。MAETok基于掩码建模(Mask Modeling)训练自编码器(...


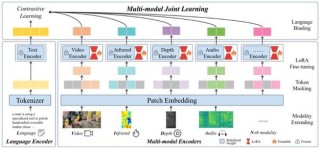
M2UGen是先进的多模态音乐理解和生成框架,由腾讯PCG ARC实验室与新加坡国立大学联合推出。结合了大型语言模型(LLM)的能力,能处理包括文本、图像、视频和音频在内的多模态输入,生成相应的音乐。...
Lyria 2 是谷歌 DeepMind 推出的第三代 AI 音乐生成模型,作为 Vertex AI 平台的核心组件,具备高保真音频生成能力,能输出 48kHz、24-bit 的专业级立体声音频。支持多种音乐风格,包括流行、...


Lyra是香港中文大学、SmartMore和香港科技大学推出的高效多模态大型语言模型(MLLM),专注于提升语音、视觉和语言模态的交互能力。Lyra基于开源大型模型、多模态LoRA模块和潜在的多模态正则化器,减少训练成本和数...

LuminaBrush 是用在图像上绘制照明效果的交互式工具。LuminaBrush基于 Flux 文生图项目,用两阶段方法:第一阶段将图像转换为“均匀照明”的外观,第二阶段根据用户涂鸦生成具体的照明效果。两阶段方法简化了学...


全部评论
留言在赶来的路上...
发表评论